
概要
2つの DataFrame を特定の列またはインデックスに基づき、横方向に結合を行なう pandas.merge() の使い方について解説します。
pandas.merge
特定の列またはインデックスに基づき、横方向の結合を行なう場合は pandas.merge() を使用します。 結合は、2つの DataFrame をインデックスまたは指定した列の値に基づき行います。
pandas.merge(left, right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=('_x', '_y'), copy=True, indicator=False, validate=None)| 名前 | 型 | デフォルト値 |
|---|---|---|
| left | DataFrame | |
| 左の DataFrame | ||
| right | DataFrame or named Series | |
| 右の DataFrame | ||
| how | {‘left’, ‘right’, ‘outer’, ‘inner’} | ‘inner’ |
| 結合方法。結合結果はキーでソートされます。 | ||
| on | label or list | |
| 結合する列名。None を指定した場合、両方の DataFrame の共通する列名で結合されます。 | ||
| left_on | label or list, or array-like | |
| 左の DataFrame の結合キーに使用する列名 |
||
| right_on | label or list, or array-like | |
| 右の DataFrame の結合キーに使用する列名 | ||
| left_index | bool | False |
| 左の DataFrame の結合キーにインデックスを使用する場合は True にします | ||
| right_index | bool | False |
| 右の DataFrame の結合キーにインデックスを使用する場合は True にします |
||
| sort | bool | False |
| 結合後、結合キーで DataFrame をソートする場合は True にします |
||
| suffixes | tuple of (str, str) | (‘_x’, ‘_y’) |
| 結合した際に両方の DataFrame で重複する列名がある場合に、列名につける接尾辞 |
||
| copy | bool | True |
| True にした場合、可能な場合はコピーを行いません | ||
| indicator | bool or str | False |
| True の場合、その行がどちらの DataFrame に存在する行なのかを示す列を追加します | ||
| validate | str, optional | |
| True の場合、結合方法をチェックします | ||
| 名前 | 説明 |
|---|---|
| DataFrame | 結合した DataFrame |
結合方法
結合は左と右の DataFrame の指定した列またはインデックスの値が同じ行を結合することで行います。
結合方法は、how で指定でき、内部結合 (inner join)、外部結合 (outer join)、左結合 (left join)、右結合 (right join) があります。データベースに出てくる結合方法と同じです。
inner: 内部結合 (デフォルト)。両方の DataFrame のキーの共通部分をとって結合する。outer: 外部結合。両方の DataFrame のキーの和集合をとって結合する。left: 左結合。左の DataFrame にあるキーのみ使用して結合する。キーの順序は保存される。right: 右結合。右の DataFrame にあるキーのみ使用して結合する。キーの順序は保存される。
import pandas as pd
from IPython.display import display
customer = pd.DataFrame(
{
"Customer": ["宮沢 春香", "伊藤 直樹", "喜嶋 康弘", "野村 智也", "松本 加奈", "田辺 結衣"],
"Product": ["Xperia", "arrows", "Galaxy", "LG", "Galaxy", "iPhone"],
}
)
product = pd.DataFrame(
{
"Product": ["Xperia", "Galaxy", "AQUOS", "Google Pixel", "LG", "HUAWEI",],
"Price": [49800, 60100, 68600, 60100, 46700, 60100],
}
)
display(customer)
display(product)| Customer | Product | |
|---|---|---|
| 0 | 宮沢 春香 | Xperia |
| 1 | 伊藤 直樹 | arrows |
| 2 | 喜嶋 康弘 | Galaxy |
| 3 | 野村 智也 | LG |
| 4 | 松本 加奈 | Galaxy |
| 5 | 田辺 結衣 | iPhone |
| Product | Price | |
|---|---|---|
| 0 | Xperia | 49800 |
| 1 | Galaxy | 60100 |
| 2 | AQUOS | 68600 |
| 3 | Google Pixel | 60100 |
| 4 | LG | 46700 |
| 5 | HUAWEI | 60100 |
内部結合
デフォルトの結合方法です。両方の DataFrame に値が存在する行のみ残します。
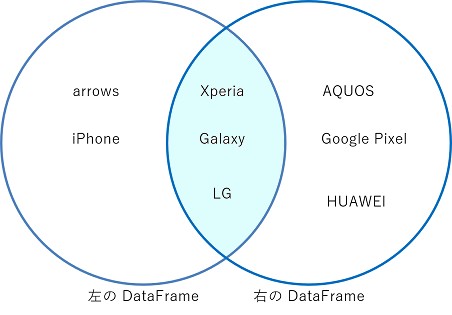
df = pd.merge(customer, product, how="left", on="Product")
df| Customer | Product | Price | |
|---|---|---|---|
| 0 | 宮沢 春香 | Xperia | 49800.0 |
| 1 | 伊藤 直樹 | arrows | NaN |
| 2 | 喜嶋 康弘 | Galaxy | 60100.0 |
| 3 | 野村 智也 | LG | 46700.0 |
| 4 | 松本 加奈 | Galaxy | 60100.0 |
| 5 | 田辺 結衣 | iPhone | NaN |
外部結合
左または右の DataFrame にしか値が存在しない行も残します。
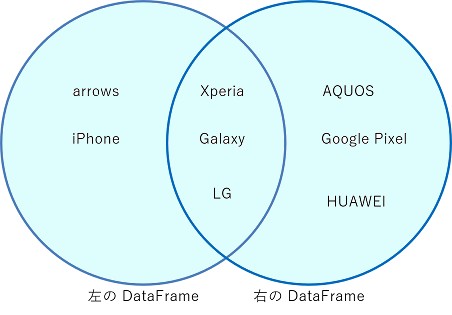
df = pd.merge(customer, product, how="outer", on="Product")
df| Customer | Product | Price | |
|---|---|---|---|
| 0 | 宮沢 春香 | Xperia | 49800.0 |
| 1 | 伊藤 直樹 | arrows | NaN |
| 2 | 喜嶋 康弘 | Galaxy | 60100.0 |
| 3 | 松本 加奈 | Galaxy | 60100.0 |
| 4 | 野村 智也 | LG | 46700.0 |
| 5 | 田辺 結衣 | iPhone | NaN |
| 6 | NaN | AQUOS | 68600.0 |
| 7 | NaN | Google Pixel | 60100.0 |
| 8 | NaN | HUAWEI | 60100.0 |
左結合 (left join)
左の DataFrame にしか値が存在しない行も残します。
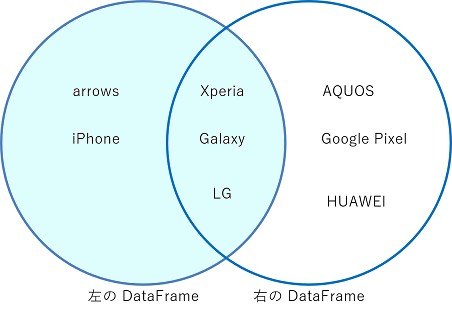
df = pd.merge(customer, product, how="left", on="Product")
df| Customer | Product | Price | |
|---|---|---|---|
| 0 | 宮沢 春香 | Xperia | 49800.0 |
| 1 | 伊藤 直樹 | arrows | NaN |
| 2 | 喜嶋 康弘 | Galaxy | 60100.0 |
| 3 | 野村 智也 | LG | 46700.0 |
| 4 | 松本 加奈 | Galaxy | 60100.0 |
| 5 | 田辺 結衣 | iPhone | NaN |
右結合 (right join)
左の DataFrame にしか値が存在しない行も残します。
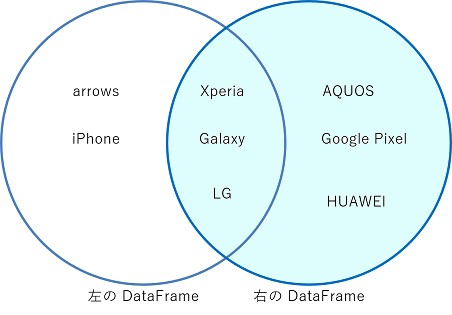
df = pd.merge(customer, product, how="right", on="Product")
df| Customer | Product | Price | |
|---|---|---|---|
| 0 | 宮沢 春香 | Xperia | 49800 |
| 1 | 喜嶋 康弘 | Galaxy | 60100 |
| 2 | 松本 加奈 | Galaxy | 60100 |
| 3 | 野村 智也 | LG | 46700 |
| 4 | NaN | AQUOS | 68600 |
| 5 | NaN | Google Pixel | 60100 |
| 6 | NaN | HUAWEI | 60100 |
結合キーの指定方法
2つの DataFrame で結合キーの列名が同じ場合
2つの DataFrame で結合キーに使用する列名が同じの場合、on で指定します。
import pandas as pd
customer = pd.DataFrame(
{
"Customer": ["宮沢 春香", "伊藤 直樹", "喜嶋 康弘", "野村 智也", "松本 加奈", "田辺 結衣"],
"Product": ["Xperia", "arrows", "Galaxy", "LG", "Galaxy", "iPhone"],
}
)
product = pd.DataFrame(
{
"Product": ["Xperia", "Galaxy", "AQUOS", "Google Pixel", "LG", "HUAWEI",],
"Price": [49800, 60100, 68600, 60100, 46700, 60100],
}
)
df = pd.merge(customer, product, on="Product")
df| Customer | Product | Price | |
|---|---|---|---|
| 0 | 宮沢 春香 | Xperia | 49800 |
| 1 | 喜嶋 康弘 | Galaxy | 60100 |
| 2 | 松本 加奈 | Galaxy | 60100 |
| 3 | 野村 智也 | LG | 46700 |
2つの DataFrame で結合キーの列名が異なる場合
2つの DataFrame で結合キーに使用する列名が異なる場合は left_on に左の DataFrame の列名、right_on に右の DataFrame の列名を指定します。
import pandas as pd
customer = pd.DataFrame(
{
"Customer": ["宮沢 春香", "伊藤 直樹", "喜嶋 康弘", "野村 智也", "松本 加奈", "田辺 結衣"],
"Product": ["Xperia", "arrows", "Galaxy", "LG", "Galaxy", "iPhone"],
}
)
product = pd.DataFrame(
{
"Model": ["Xperia", "Galaxy", "AQUOSL", "Google Pixel", "LG", "HUAWEI"],
"Price": [49800, 60100, 68600, 60100, 46700, 60100],
}
)
df = pd.merge(customer, product, left_on="Product", right_on="Model")
df| Customer | Product | Model | Price | |
|---|---|---|---|---|
| 0 | 宮沢 春香 | Xperia | Xperia | 49800 |
| 1 | 喜嶋 康弘 | Galaxy | Galaxy | 60100 |
| 2 | 松本 加奈 | Galaxy | Galaxy | 60100 |
| 3 | 野村 智也 | LG | LG | 46700 |
インデックスを結合キーとして使用する場合
左側の DataFrame でインデックスをキーとして使用する場合、left_index=True を指定します。
同様に、右側の DataFrame でインデックスをキーとして使用する場合、right_index=True を指定します。
import pandas as pd
product = pd.DataFrame(
{"Product": ["Xperia", "arrows", "Galaxy", "LG", "Galaxy", "iPhone"]}
)
price = pd.DataFrame(
{
"ProductId": [1, 2, 3, 4, 5, 6],
"Price": [49800, 60100, 68600, 60100, 46700, 60100],
}
)
df = pd.merge(product, price, left_index=True, right_on="ProductId")
df| Product | ProductId | Price | |
|---|---|---|---|
| 0 | arrows | 1 | 49800 |
| 1 | Galaxy | 2 | 60100 |
| 2 | LG | 3 | 68600 |
| 3 | Galaxy | 4 | 60100 |
| 4 | iPhone | 5 | 46700 |
結合後にソートする
sort=True を指定した場合、結合後、結合キーで DataFrame をソートします。
import pandas as pd
customer = pd.DataFrame(
{
"Customer": ["宮沢 春香", "伊藤 直樹", "喜嶋 康弘", "野村 智也", "松本 加奈", "田辺 結衣"],
"Product": ["Xperia", "arrows", "Galaxy", "LG", "Galaxy", "iPhone"],
}
)
product = pd.DataFrame(
{
"Product": ["Xperia", "Galaxy", "AQUOS", "Google Pixel", "LG", "HUAWEI",],
"Price": [49800, 60100, 68600, 60100, 46700, 60100],
}
)
df = pd.merge(customer, product, on="Product", sort=True)
df| Customer | Product | Price | |
|---|---|---|---|
| 0 | 喜嶋 康弘 | Galaxy | 60100 |
| 1 | 松本 加奈 | Galaxy | 60100 |
| 2 | 野村 智也 | LG | 46700 |
| 3 | 宮沢 春香 | Xperia | 49800 |
重複する列名の接尾辞 (suffix) を指定する。
結合した際、どちらの DataFrame にも存在する列名は接尾辞を付加して、区別されます。
デフォルトでは左の DataFrame の列は _x、右の DataFrame の列は _y が付加されますが、suffixes 引数に (左の DataFrame の接尾辞, 右の DataFrame の接尾辞) を指定することで変更できます。
import pandas as pd
from IPython.display import display
left = pd.DataFrame({"A": [1, 2, 3], "B": [1, 2, 3]})
right = pd.DataFrame({"A": [1, 2, 3], "B": [1, 2, 3]})
# デフォルト
df = pd.merge(left, right, on="A")
display(df)
# suffixes を指定した場合
df = pd.merge(left, right, on="A", suffixes=("_left", "_right"))
display(df)| A | B_x | B_y | |
|---|---|---|---|
| 0 | 1 | 1 | 1 |
| 1 | 2 | 2 | 2 |
| 2 | 3 | 3 | 3 |
| A | B_left | B_right | |
|---|---|---|---|
| 0 | 1 | 1 | 1 |
| 1 | 2 | 2 | 2 |
| 2 | 3 | 3 | 3 |
行が結合前のどちらの DataFrame 由来のものかどうかを示す列を追加する
indicator=True とした場合、その行が左、右の一方、または両方に含まれるかどうかを示す列を追加します。
left_only: 左の DataFrame にのみ存在する行right_only: 右の DataFrame にのみ存在する行both: 両方の DataFrame に存在する行
import pandas as pd
customer = pd.DataFrame(
{
"Customer": ["宮沢 春香", "伊藤 直樹", "喜嶋 康弘", "野村 智也", "松本 加奈", "田辺 結衣"],
"Product": ["Xperia", "arrows", "Galaxy", "LG", "Galaxy", "iPhone"],
}
)
product = pd.DataFrame(
{
"Product": ["Xperia", "Galaxy", "AQUOS", "Google Pixel", "LG", "HUAWEI"],
"Price": [49800, 60100, 68600, 60100, 46700, 60100],
}
)
df = pd.merge(customer, product, how="outer", on="Product", indicator=True)
df| Customer | Product | Price | _merge | |
|---|---|---|---|---|
| 0 | 宮沢 春香 | Xperia | 49800.0 | both |
| 1 | 伊藤 直樹 | arrows | NaN | left_only |
| 2 | 喜嶋 康弘 | Galaxy | 60100.0 | both |
| 3 | 松本 加奈 | Galaxy | 60100.0 | both |
| 4 | 野村 智也 | LG | 46700.0 | both |
| 5 | 田辺 結衣 | iPhone | NaN | left_only |
| 6 | NaN | AQUOS | 68600.0 | right_only |
| 7 | NaN | Google Pixel | 60100.0 | right_only |
| 8 | NaN | HUAWEI | 60100.0 | right_only |
結合を検証する
validate を指定することで結合が指定した条件 (例: 1対多) を満たしているかどうか検証し、違反している場合はエラーになります。
one_to_oneまたは1:1: 1対1one_to_manyまたは1:m: 1対多many_to_oneまたはm:1: 多対1many_to_manyまたはm:m: 多対多
import pandas as pd
customer = pd.DataFrame(
{
"Customer": ["宮沢 春香", "伊藤 直樹", "喜嶋 康弘", "野村 智也", "松本 加奈", "田辺 結衣"],
"Product": ["Xperia", "arrows", "Galaxy", "LG", "Galaxy", "iPhone"],
}
)
product = pd.DataFrame(
{
"Product": ["Xperia", "Galaxy", "AQUOS", "Google Pixel", "LG", "HUAWEI"],
"Price": [49800, 60100, 68600, 60100, 46700, 60100],
}
)
df = pd.merge(customer, product, how="outer", on="Product", validate="many_to_one")
df| Customer | Product | Price | |
|---|---|---|---|
| 0 | 宮沢 春香 | Xperia | 49800.0 |
| 1 | 伊藤 直樹 | arrows | NaN |
| 2 | 喜嶋 康弘 | Galaxy | 60100.0 |
| 3 | 松本 加奈 | Galaxy | 60100.0 |
| 4 | 野村 智也 | LG | 46700.0 |
| 5 | 田辺 結衣 | iPhone | NaN |
| 6 | NaN | AQUOS | 68600.0 |
| 7 | NaN | Google Pixel | 60100.0 |
| 8 | NaN | HUAWEI | 60100.0 |
コメント