
概要
Beautiful Soup で条件を指定して要素を検索する方法を解説します。
関連記事
[blogcard url=”https://pystyle.info/scraping-beautiful-soup-how-to-edit-dom-tree”]
[blogcard url=”https://pystyle.info/scraping-beautiful-soup-how-to-refer-elements”]
機能一覧
引数で検索条件を指定する find 系のメソッドと CSS セレクタで検索条件を指定する select 系のメソッドがあります。
find(), find_parent(), find_next_sibling(), find_previous_sibling(), select_one()は条件に該当する最初に見つかった要素を返します。find_all(), find_parents(), find_next_siblings(), find_previous_siblings(), select()は条件に該当するすべての要素を一覧で返すようになっています。find系のメソッドは検索範囲によって使い分けます。
| 検索範囲 | 返り値 | |
|---|---|---|
find() |
子孫要素 | 条件に該当する最初に見つかった要素 |
find_all() |
子孫要素 | 条件に該当するすべての要素 |
find_parent() |
先祖要素 | 条件に該当する最初に見つかった要素 |
find_parents() |
先祖要素 | 条件に該当するすべての要素 |
find_next_sibling() |
この要素より前のすべての兄弟要素 | 条件に該当する最初に見つかった要素 |
find_next_siblings() |
この要素より前のすべての兄弟要素 | 条件に該当するすべての要素 |
find_previous_sibling() |
この要素より後のすべての兄弟要素 | 条件に該当する最初に見つかった要素 |
find_previous_siblings() |
この要素より後のすべての兄弟要素 | 条件に該当するすべての要素 |
select_one() |
子孫要素 | 条件に該当する最初に見つかった要素 |
select() |
子孫要素 | 条件に該当するすべての要素 |
サンプルの HTML
以下の HTML をサンプルとして使用します。
html = """
<html>
<head>
<title>ニュース</title>
</head>
<body>
<h1>ニュース</h1>
<div class="topic">
<h2>トピック一覧</h2>
<ul class="list" id="menu">
<li>トピック1</li>
<li>トピック2</li>
</ul>
</div>
<div class="images">
<h2>注目の画像</h2>
<ul class="list">
<li><img src="sample1.jpg" alt="画像1"></li>
<li><img src="sample2.jpg" alt="画像2"></li>
</ul>
</div>
<p>お気に入りに<a href="sample.com">このサイト</a>を登録してください。</p>
</body>
</html>
"""Beautiful Soup では、HTML テキストを解析し、以下のような DOM ツリーで表現します。要素の検索、追加はこの階層構造を元に行いますので、解析する HTML の階層構造がどうなっているかをまず理解するようにしましょう。
import re
import bs4
from anytree import Node, RenderTree
from bs4 import BeautifulSoup
html = re.sub(r"^\s+", "", html, flags=re.MULTILINE).replace("\n", "")
soup = BeautifulSoup(html)
root = Node("root", type_=soup.__class__.__name__)
def traverse(parent, soupNode, depth=0):
if isinstance(soupNode, bs4.NavigableString):
name = repr(soupNode.string)
else:
name = soupNode.name
anyNode = Node(name, parent=parent, type_=soupNode.__class__.__name__)
if hasattr(soupNode, "children"):
for child in soupNode.children:
traverse(anyNode, child, depth + 1)
traverse(root, soup.html)
for pre, fill, node in RenderTree(root):
print("{}{} ({})".format(pre, node.name, node.type_))root (BeautifulSoup)
└── html (Tag)
├── head (Tag)
│ └── title (Tag)
│ └── 'ニュース' (NavigableString)
└── body (Tag)
├── h1 (Tag)
│ └── 'ニュース' (NavigableString)
├── div (Tag)
│ ├── h2 (Tag)
│ │ └── 'トピック一覧' (NavigableString)
│ └── ul (Tag)
│ ├── li (Tag)
│ │ └── 'トピック1' (NavigableString)
│ └── li (Tag)
│ └── 'トピック2' (NavigableString)
├── div (Tag)
│ ├── h2 (Tag)
│ │ └── '注目の画像' (NavigableString)
│ └── ul (Tag)
│ ├── li (Tag)
│ │ └── img (Tag)
│ └── li (Tag)
│ └── img (Tag)
└── p (Tag)
├── 'お気に入りに' (NavigableString)
├── a (Tag)
│ └── 'このサイト' (NavigableString)
└── 'を登録してください。' (NavigableString)
find 系の関数
find 系の関数は、検索範囲が異なるだけで、引数の指定方法は共通です。
find() と find_all()
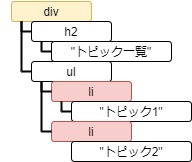
Tag.find_all() は、子孫要素を検索し、条件に該当するすべての要素を bs4.element.ResultSet オブジェクトで返します。これはリストと同様で iterate やスライスが行えます。
from bs4 import BeautifulSoup
soup = BeautifulSoup(html)
# 名前が "li" の要素を検索する。
ret = soup.find_all("li")
print(ret)
# スライスなどインデックス操作もリスト同様に行える。
print(ret[0])
print(ret[1:])[<li>トピック1</li>, <li>トピック2</li>, <li><img alt="画像1" src="sample1.jpg"/></li>, <li><img alt="画像2" src="sample2.jpg"/></li>] <li>トピック1</li> [<li>トピック2</li>, <li><img alt="画像1" src="sample1.jpg"/></li>, <li><img alt="画像2" src="sample2.jpg"/></li>]
条件に該当する要素が1つしかない場合でも返り値は bs4.element.ResultSet オブジェクトになります。
# 名前が "p" の要素を検索する。
print(soup.find_all("p"))[<p>お気に入りに<a href="sample.com">このサイト</a>を登録してください。</p>]
一方、Tag.find() は Tag.find_all() と異なり、条件に該当する最初に見つかった要素を返します。
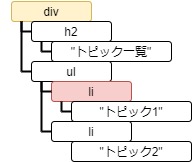
# 名前が "li" の要素を検索し、最初に見つかった要素を返す。
print(soup.find("li"))<li>トピック1</li>
4つの指定方法
find 系のメソッドは条件の指定方法として、次の4つがあります。
- 名前で検索:
name引数で指定 - 属性で検索:
attrs引数または属性=値で指定 - 値で検索:
stringで指定
各引数では、次の指定方法があります。
- True
- 値
- 値のリスト
- 正規表現 (
re.Patternオブジェクト) - bool 関数
指定した名前の要素を検索する
検索する要素名を name 引数で指定します。要素名はリストで複数指定できます。
# 名前が "p" の要素を検索する。
print(soup.find_all("p"))
# 名前が "p" または "img" の要素を検索する。
print(soup.find_all(["p", "img"]))[<p>お気に入りに<a href="sample.com">このサイト</a>を登録してください。</p>] [<img alt="画像1" src="sample1.jpg"/>, <img alt="画像2" src="sample2.jpg"/>, <p>お気に入りに<a href="sample.com">このサイト</a>を登録してください。</p>]
要素名の指定には、正規表現が利用できます。
import re
# 名前が h から始まる要素を検索する。
for tag in soup.find_all(re.compile("^h")):
print(tag.name, end=" ")html head h1 h2 h2
True を指定することで、すべての要素を取得できます。
for tag in soup.find_all(True):
print(tag.name, end=" ")html head title body h1 div h2 ul li li div h2 ul li img li img p a
要素を受け取り、bool 値を返す関数を指定すると、関数が True を返す要素を検索します。
# 名前の長さが4の要素を検索する
for tag in soup.find_all(lambda x: x and len(x.name) == 4):
print(tag.name, end=" ")html head body
指定した属性を持つ要素を検索する
引数に 属性名=値 を指定することで、その属性値を持つ要素を検索します。
ただし、属性 class を指定する場合、class は Python の予約語なので、代わりに class_ を使用します。
# "class" 属性の値が "list" の要素を検索する。
for tag in soup.find_all(True, class_="list"):
print(tag.name)ul ul
複雑の属性を指定できます。
# "class" 属性の値が "list" で "id" 属性の値が "menu" の要素を検索する。
for tag in soup.find_all(True, class_="list", id="menu"):
print(tag.name)ul
正規表現を使用できます。
# "class" 属性の値が "l" で始まる要素を検索する。
for tag in soup.find_all(True, class_=re.compile(r"^l")):
print(tag.name)ul ul
属性値を True にすることで、その属性を持つ要素を検索します。
# "class" 属性を持つ要素を検索する。
for tag in soup.find_all(class_=True):
print(tag.name)div ul div ul
属性値を受け取り、bool 値を返す関数を指定すると、関数が True を返す要素を検索します。
# "class" 属性の値の長さが4の要素を検索する。
print(soup.find_all(class_=lambda x: x and len(x) == 4))[<ul class="list" id="menu"><li>トピック1</li><li>トピック2</li></ul>, <ul class="list"><li><img alt="画像1" src="sample1.jpg"/></li><li><img alt="画像2" src="sample2.jpg"/></li></ul>]
attrs 引数でも属性の条件を指定できます。
# "class" 属性の値が "list" で "id" 属性の値が "menu" の要素を検索する。
print(soup.find_all(True, attrs={"class": "list", "id": "menu"}))[<ul class="list" id="menu"><li>トピック1</li><li>トピック2</li></ul>]
指定した値を持つ要素を検索する
string 引数のみ指定した場合は、指定した値をもつ NavigableString オブジェクトを返します。
name 引数で要素名も指定した場合、指定した値を Tag.string に持つ要素を返します。値はリストで複数指定できます。
# 値が "トピック1" である要素を検索し、その値を NavigableString オブジェクトで返す。
print(soup.find_all(string="トピック1"))
# 値が "トピック1" で名前が "li" である要素を取得する。
print(soup.find_all("li", string="トピック1"))
# 値が "トピック1" または "トピック2" で名前が "li" である要素を取得する。
print(soup.find_all("li", string=["トピック1", "トピック2"]))['トピック1'] [<li>トピック1</li>] [<li>トピック1</li>, <li>トピック2</li>]
正規表現も使用できます。
# 値が "トピック" で始まる要素を検索する。
print(soup.find_all(string=re.compile(r"^トピック")))['トピック一覧', 'トピック1', 'トピック2']
値を受け取り、bool 値を返す関数を指定すると、関数が True を返す要素を検索します。
# 値の長さが5である要素を取得する。
print(soup.find_all("li", string=lambda x: x and len(x) == 5))[<li>トピック1</li>, <li>トピック2</li>]
返り値の要素数の上限を指定する
limit 引数で上限を設定できます。
# 条件に該当する要素を検索し、最初の3つの要素を返す。
print(soup.find_all("li", limit=3))[<li>トピック1</li>, <li>トピック2</li>, <li><img alt="画像1" src="sample1.jpg"/></li>]
再帰的に検索する深さを指定する
デフォルトでは、find_all() を呼び出した要素の子孫要素がすべて検索となりますが、recursive=False を指定した場合は、その子要素のみを検索対象とします。
print(soup.find_all("h1"))
# 検索対象を子要素に限定する。
print(soup.find_all("h1", recursive=False))[<h1>ニュース</h1>] []
Tag オブジェクトの呼び出しメソッド
bs4.BeautifulSoup オブジェクトまたは bs4.element.Tag オブジェクトの呼び出しメソッドは、find_all() と同じ意味になります。
print(soup.find_all("h1"))
print(soup("h1"))
print(soup.html("h1"))[<h1>ニュース</h1>] [<h1>ニュース</h1>] [<h1>ニュース</h1>]
select 系のメソッド
select() 及び select_one() は、検索条件を CSS セレクタで指定します。CSS セレクタを使用することで、「div タグの子要素の h1 タグ」「div タグの2番目の子要素」といった find 系のメソッドでは複数行のコードが必要となる検索処理を1つの関数呼び出しで実現できます。
CSS セレクタの指定方法は沢山あるので、「CSS セレクタ」で検索してでてくる情報を参照してください。
コメント