
概要
OpenCV で特徴点マッチングを行う方法について、解説します。
特徴点マッチングを利用することで、物体の位置の検出などに応用できます。
特徴点検出
画像のうち、追跡、比較に利用することができる部分を特徴 (feature / keypoint) といい、画像から特徴を検出することを特徴検出 (feature detection) といいます。
特徴点検出を行う
import cv2
from IPython.display import Image, display
def imshow(img):
"""ndarray 配列をインラインで Notebook 上に表示する。"""
ret, encoded = cv2.imencode(".jpg", img)
display(Image(encoded))特徴点検出器を作成する
まず、画像から特徴を検出を行う特徴検出器を作成します。 OpenCV では、以下の関数で特徴検出器を作成できます。
- cv2.AKAZE_create(): AKAZE 特徴量
- cv2.BRISK_create(): BRISK 特徴量
- cv2.KAZE_create(): KAZE 特徴量
- cv2.ORB_create(): ORB 特徴量
# OBR 特徴検出器を作成する。
detector = cv2.ORB_create()特徴点及び特徴量記述子を計算する
作成した特徴検出器の detect() で画像から特徴点 (feature keypoints) を検出できます。
keypoints = cv2.Feature2D.detect(image[, mask])| 名前 | 型 | デフォルト値 |
|---|---|---|
| image | ndarray | |
| 画像 | ||
| mask | ndarray | None |
| マスク画像 | ||
| 名前 | 説明 | ||
|---|---|---|---|
| keypoints | 特徴点を表す KeyPoint オブジェクトのリスト | ||
検出した特徴点のリストは cv2.drawKeypoints() で画像に描画して確認できます。

# 画像を読み込む。
img = cv2.imread("sample1.jpg")
# 特徴点を検出する。
kp = detector.detect(img)
# 特徴点を描画する。
dst = cv2.drawKeypoints(img, kp, None)
imshow(dst)
特徴点が検出できたら、compute() でその特徴点の特徴記述子 (feature descriptor) を計算します。
keypoints, descriptors = cv2.Feature2D.compute(images, keypoints)| 名前 | 型 | デフォルト値 |
|---|---|---|
| image | ndarray | |
| 画像 | ||
| keypoints | list of KeyPoint | |
| 特徴点を表す KeyPoint オブジェクトのリスト | ||
| 名前 | 説明 | ||
|---|---|---|---|
| keypoints | 特徴点を表す KeyPoint オブジェクトのリスト | ||
| descriptors | 形状が (特徴点の数, 特徴量記述子の次元数) の numpy 配列。各特徴点に対応する特徴記述子。 | ||
# 各特徴点の特徴量記述子を計算する。
kp, desc = detector.compute(img, kp)
print(len(kp), desc.shape)481 (481, 32)
detectAndCompute() で、特徴点の検出と特徴量記述子の計算を一度に行えます。
返り値は (特徴点の一覧, 各特徴点の特徴量記述子) のタプルになります。
keypoints, descriptors = cv2.Feature2D.detectAndCompute(image, mask)| 名前 | 型 | デフォルト値 |
|---|---|---|
| image | ndarray | |
| 画像 | ||
| mask | ndarray | |
| マスク画像 | ||
| 名前 | 説明 | ||
|---|---|---|---|
| keypoints | 特徴点を表す KeyPoint オブジェクトのリスト | ||
| descriptors | 形状が (特徴点の数, 特徴量記述子の次元数) の numpy 配列。各特徴点に対応する特徴記述子。 | ||
# 特徴点を検出する。
kp, desc = detector.detectAndCompute(img, None)
print(len(kp), desc.shape)481 (481, 32)
特徴点マッチングを行う
2 つの画像に対して、特徴点の検出及び特徴量記述子の計算を行い、類似度が高い特徴点同士をマッチングすることを特徴点マッチング (feature matching) といいます。
OpenCV では、次の 2 種類のマッチング器が提供されています。
- cv2.BFMatcher: 総当りによるマッチング (Brute Force Matching) を行う。
- cv2.FlannBasedMatcher 近似近傍探索手法 Flann によるマッチングを行う。
今回は、総当りによるマッチングが行える cv2.BFMatcher を紹介します。

まず、2 つの画像から特徴点及び特徴記述子をそれぞれ抽出します。
# 画像を読み込む。
img1 = cv2.imread("sample1.jpg")
img2 = cv2.imread("sample2.jpg")
# 特徴点及び特徴量記述子を検出する。
kp1, desc1 = detector.detectAndCompute(img1, None)
kp2, desc2 = detector.detectAndCompute(img2, None)
print(desc1.shape)(481, 32)
最近傍マッチング
マッチング器 cv2.BFMatcher オブジェクトを作成し、2 つの画像の特徴記述子を BFMatcher.match() に渡して、マッチングを行います。
matches = cv2.DescriptorMatcher.match(queryDescriptors, trainDescriptors[, mask])| 名前 | 型 | デフォルト値 |
|---|---|---|
| queryDescriptors | ndarray | |
| クエリ用の特徴記述子 | ||
| trainDescriptors | ndarray | |
| 学習用の特徴記述子 | ||
| mask | ndarray | None |
| マスク画像 | ||
| 名前 | 説明 | ||
|---|---|---|---|
| matches | マッチング情報を表す [DMatch](https://docs.opencv.org/master/d4/de0/classcv_1_1DMatch.html) オブジェクトのリスト | ||
# マッチング器を作成する。
bf = cv2.BFMatcher(cv2.NORM_HAMMING)
# マッチングを行う。
matches = bf.match(desc1, desc2)
print(len(matches))481
DMatch オブジェクトは、次の属性を持っています。
distance: 特徴量記述子の距離queryIdx: クエリ記述子 (match(desc1, desc2)と渡した場合、desc1のインデックス)trainIdx: 学習記述子 (match(desc1, desc2)と渡した場合、desc2のインデックス)
matches の最初の DMatch オブジェクトを見てみましょう。
m = matches[0]
print(f"distance: {m.distance}, trainIdx: {m.trainIdx}, queryIdx: {m.queryIdx}")distance: 3.0, trainIdx: 15, queryIdx: 0
これは img1 の特徴点 kp1[0] と最も距離が近い img2 の特徴点は kp2[15] であることを表しています。
また、その 2 つの特徴点の特徴量記述子同士の距離が 3 であることを表しており、この距離が近いほど、2 つの特徴点は似ていると解釈できます。
# 特徴点の対応関係
query_pt, train_pt = kp1[m.queryIdx], kp2[m.trainIdx]
# 特徴量記述子の対応関係
query_desc, train_desc = desc1[m.queryIdx], desc2[m.trainIdx]match() による特徴点マッチングの結果は、cv2.drawMatches() で可視化できます。
# マッチング結果を描画する。
dst = cv2.drawMatches(img1, kp1, img2, kp2, matches, None)
imshow(dst)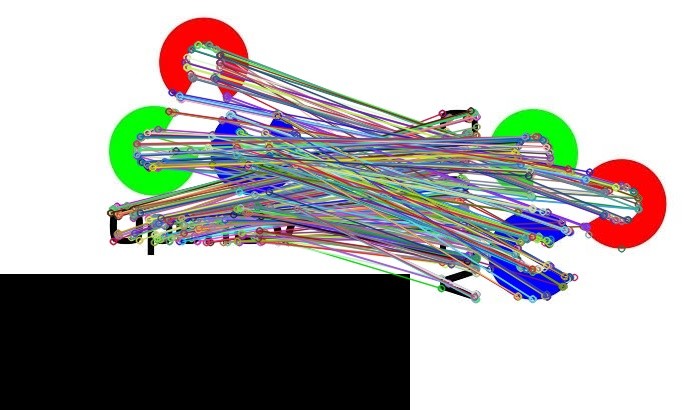
k 近傍法によるマッチング
BFMatcher.knnMatch() で k 近傍法によるマッチングも行えます。
この関数は、queryDescriptors と距離が近い上位 $k$ 個の特徴点を trainDescriptors から探します。
返り値は、各要素がマッチング情報 DMatch オブジェクトである形状が (特徴点の数, k) のリストとなっています。
import cv2
img1 = cv2.imread("sample1.jpg")
img2 = cv2.imread("sample2.jpg")
# OBR 特徴量検出器を作成する。
detector = cv2.ORB_create()
# 特徴点を検出する。
kp1, desc1 = detector.detectAndCompute(img1, None)
kp2, desc2 = detector.detectAndCompute(img2, None)
# マッチング器を作成する。
bf = cv2.BFMatcher(cv2.NORM_HAMMING)
# マッチングを行う。
matches = bf.knnMatch(desc1, desc2, k=2)matches の最初の DMatch オブジェクトを見てみましょう。
m = matches[0]
print(m)
for n in m:
# 特徴点の対応関係
query_pt, train_pts = kp1[n.queryIdx], kp2[n.trainIdx]
# 特徴量記述子の対応関係
query_desc, train_desc = desc1[n.queryIdx], desc2[n.trainIdx]
print(f"distance: {n.distance}, trainIdx: {n.trainIdx}, queryIdx: {n.queryIdx}")(< cv2.DMatch 0x7f7c4b4970d0>, < cv2.DMatch 0x7f7c4b4e4ad0>) distance: 3.0, trainIdx: 15, queryIdx: 0 distance: 30.0, trainIdx: 9, queryIdx: 0
これは img1 の特徴点 kp1[0] と 1 番目、2 番目に距離が近い img2 の特徴点はそれぞれ kp2[15], kp2[9] であることを表しています。
knnMatch() による特徴点マッチングの結果は、cv2.drawMatchesKnn() で可視化できます。
# マッチング結果を描画する。
dst = cv2.drawMatchesKnn(img1, kp1, img2, kp2, matches, None)
imshow(dst)
信頼性の低いマッチング結果を除く
マッチング結果から信頼性の低いものを除く方法を 2 つ紹介します。
クロスチェック
crossCheck=True とした場合、マッチングの際にクロスチェックを行います。
queryDescriptors と最も距離が近い特徴点を trainDescriptors から探すのと同様、
trainDescriptors と最も距離が近い特徴点を queryDescriptors から探して、結果が両者で一致した場合のみマッチングしたと判定します。
同じ距離の特徴量が複数ある場合は、訓練集合とテスト集合を入れ替えた際のマッチング結果が変わってくるため、クロスチェックを有効にした場合、このようなマッチングは信頼性に欠けるので除外します。
この方法は、最近傍探索を行う場合 (BFMatcher.match() または BFMatcher.knnMatch(k=1)) のみ有効です。
$k \ge 2$ で実行した場合、error: (-215:Assertion failed) K == 1 && update == 0 && mask.empty() in function 'batchDistance' とエラーになります。
import cv2
img1 = cv2.imread("sample1.jpg")
img2 = cv2.imread("sample2.jpg")
# OBR 特徴量検出器を作成する。
detector = cv2.ORB_create()
# 特徴点を検出する。
kp1, desc1 = detector.detectAndCompute(img1, None)
kp2, desc2 = detector.detectAndCompute(img2, None)
# マッチング器を作成する。
bf = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=True)
# マッチングを行う。
matches = bf.match(desc1, desc2)
# マッチング結果を描画する。
dst = cv2.drawMatches(img1, kp1, img2, kp2, matches, None)
imshow(dst)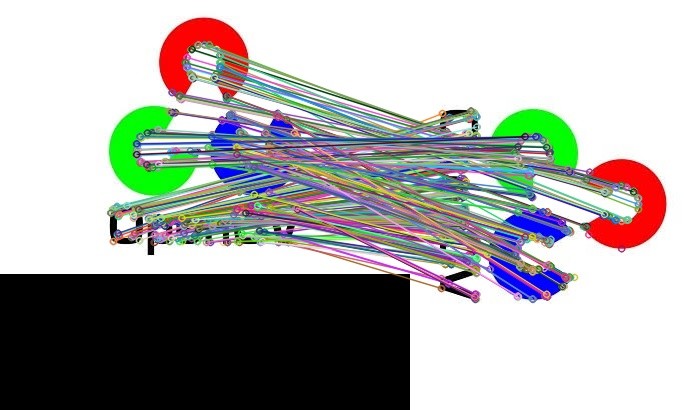
レシオテスト
レシオテスト (ratio test) は SIFT 特徴量の論文 で紹介されている方法です。
この方法は BFMatcher.knnMatch(k=2) で 2 近傍探索によるマッチングを行なう場合に最も近い距離と 2 番目に近い距離の比率が閾値以上のマッチング結果のみを残す方法です。
1 番目に近い距離と 2 番目に近い距離の差があまりない場合、信頼性に欠けるので除外します。
import cv2
img1 = cv2.imread("sample1.jpg")
img2 = cv2.imread("sample2.jpg")
# OBR 特徴量検出器を作成する。
detector = cv2.ORB_create()
# 特徴点を検出する。
kp1, desc1 = detector.detectAndCompute(img1, None)
kp2, desc2 = detector.detectAndCompute(img2, None)
# マッチング器を作成する。
bf = cv2.BFMatcher(cv2.NORM_HAMMING)
# マッチングを行う。
matches = bf.knnMatch(desc1, desc2, k=2)
# レシオテストを行う。
good_matches = []
thresh = 0.7
for first, second in matches:
if first.distance < second.distance * thresh:
good_matches.append(first)
# マッチング結果を描画する。
dst = cv2.drawMatches(img1, kp1, img2, kp2, good_matches, None)
imshow(dst)
距離関数
特徴量記述子の種類によって、適した距離関数が変わってきます。 リファレンスによると、特徴量記述子によって以下のように使い分けるとよいそうです。
- cv2.NORM_L1, cv2.NORM_L2: SIFT、SURF
- cv2.NORM_HAMMING: ORB, BRISK, BRIEF, AKAZE
- cv2.NORM_HAMMING2: パラメータ WTA_K を 3 または 4 に設定した ORB
コメント