
概要
AlexNet について解説し、Pytroch の実装を紹介します。
AlexNet
ResNet は、画像認識のコンテスト ILSVRC 2012 にて、優勝した CNN ネットワークモデルです。下記、論文に基づいて解説します。
ImageNet Classification with Deep Convolutional Neural Networks
Local Response Norm
現在は層の出力の正規化は Batch Normalization が主流ですが、当時はまだなかったので Local Response Norm が使われていました。Local Response Norm は入力を次の式で変換する層です。
$$ b_c = a_c \left(k + \frac{\alpha}{n} \sum_{c’ = \max(0, c – n / 2)}^{\min(N – 1, c + n / 2)} a_{c’}^2 \right)^{-\beta} $$- $a_c$: Local Response Norm の入力。特徴マップのある位置のチャンネル $c$ の値。
- $b_c$: Local Response Norm の出力。
- $\alpha, \beta, k$: パラメータ
- $n$: サイズ。平均をとる範囲のこと。
- $N$: 特徴マップのチャンネル数

特徴マップのある位置のチャンネル $c$ の値を $a_c$ とすると出力 $b_c$ は、チャンネル方向の $\frac{n}{2}$ の範囲の二乗の平均を $\frac{1}{n} \sum_{c’ = \max(0, c – n / 2)}^{\min(N – 1, c + n / 2)} a_{c’}^2$ で計算し、それを $\alpha, \beta, k$ という3つのパラメータで調整した値を $a_c$ に乗算して計算しています。$\min(N – 1, c + n / 2), \max(0, c – n / 2)$ は平均をとる範囲が $[0, N – 1]$ からはみ出さないようにするためについています。
Pytorch では、LocalResponseNorm で実装されています。
torch.nn.LocalResponseNorm(size, alpha=0.0001, beta=0.75, k=1.0)AlexNet の構造
以下が論文に記載された AlexNet の構造です。当時の GTX 580 はメモリが3Gしかなかったため、1つの GPU にモデルを載せることができませんでした。そのため、論文では出力数を半分にしたモデルを作成し、最後に結合する構造になっていますが、今の GPU はメモリが十分あるので、チャンネル数を2つ合わせた1つのモデルにします。
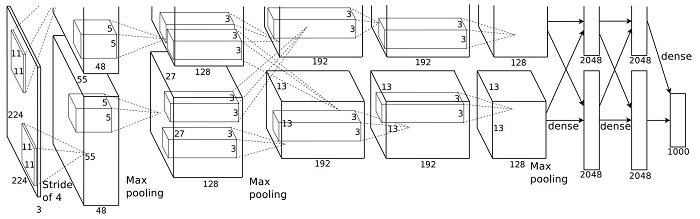
- 論文中の上図ではモデルの入力サイズが (224×224) となっていますが、その場合 kernel_size=11, stride=4 の畳み込みを行った場合、出力サイズが (54×54) となり、論文と一致しません。そのため、入力サイズは (227×227) の typo であると思われます。
- Local Response Norm のパラメータは論文の Section 3.3 に従い、$n = 5, \alpha=0.0001, \beta=0.75, k=2$ とします。
- Dropout の確率は論文の Section 4.2 に従い、$p=0.5$ とします。
- 重みの初期化方法は論文の Section 5 に従い、畳み込み層は $\mu=0, \sigma=0.01$ のガウス分布、2、4、5個目の畳み込み層のバイアスは1、その他の層のバイアスは0で初期化します。
import torch
import torch.nn as nn
class AlexNetOriginal(nn.Module):
def __init__(self, num_classes=1000):
super().__init__()
self.net = nn.Sequential(
nn.Conv2d(3, 96, kernel_size=11, stride=4), # conv1
nn.ReLU(inplace=True),
nn.LocalResponseNorm(size=5, alpha=1e-4, beta=0.75, k=2),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(96, 256, kernel_size=5, padding=2), # conv2
nn.ReLU(inplace=True),
nn.LocalResponseNorm(size=5, alpha=1e-4, beta=0.75, k=2),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(256, 384, kernel_size=3, padding=1), # conv3
nn.ReLU(inplace=True),
nn.Conv2d(384, 384, kernel_size=3, padding=1), # conv4
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1), # conv5
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
self.classifier = nn.Sequential(
nn.Linear(in_features=(256 * 6 * 6), out_features=4096),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5, inplace=True),
nn.Linear(in_features=4096, out_features=4096),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5, inplace=True),
nn.Linear(in_features=4096, out_features=num_classes),
)
self._init_weights()
def _init_weights(self):
for layer in self.net:
if isinstance(layer, nn.Conv2d):
nn.init.normal_(layer.weight, mean=0, std=0.01)
nn.init.constant_(layer.bias, 0)
# 2, 4, 5個目の Conv2d のバイアスは1で初期化する。
nn.init.constant_(self.net[4].bias, 1)
nn.init.constant_(self.net[10].bias, 1)
nn.init.constant_(self.net[12].bias, 1)torchvision の AlexNet
torchvision の AlexNet は上記で紹介したものと以下の点が異なります。
- 入力サイズは (227, 227) から (224, 224) にし、代わりに最初の Conv2d に padding=2 を入れて出力が (55, 55) になるように調整しています。
- 5つの畳み込み層の出力数がそれぞれ
96, 256, 384, 384, 256から64, 192, 384, 256, 256になっています。 - LocalResponseNorm はなくなっています。
- 入力サイズが (224, 224) より大きい場合、最後の畳み込み層の出力が (6, 6) より大きくなります。次の全結合層は (6, 6) の入力を想定しているため、AdaptiveAvgPool2d を適用し、(6, 6) にプーリングします。
- Dropout の場所が
fc1->ReLU->Dropout->fc2->ReLU->Dropout->fc3ではなく、Dropout->fc1->ReLU->Dropout->fc2->ReLU->fc3になっています。
import torch
import torch.nn as nn
class AlexNet(nn.Module):
def __init__(self, num_classes=1000):
super().__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(64, 192, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(192, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
self.avgpool = nn.AdaptiveAvgPool2d((6, 6))
self.classifier = nn.Sequential(
nn.Dropout(p=0.5),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes),
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return xtorchinfo を使用して、各層の出力サイズを確認します。
import torchinfo
model = AlexNet()
torchinfo.summary(model, (1, 3, 416, 416), col_width=17)==========================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================
AlexNet -- --
├─Sequential: 1-1 [1, 256, 12, 12] --
│ └─Conv2d: 2-1 [1, 64, 103, 103] 23,296
│ └─ReLU: 2-2 [1, 64, 103, 103] --
│ └─MaxPool2d: 2-3 [1, 64, 51, 51] --
│ └─Conv2d: 2-4 [1, 192, 51, 51] 307,392
│ └─ReLU: 2-5 [1, 192, 51, 51] --
│ └─MaxPool2d: 2-6 [1, 192, 25, 25] --
│ └─Conv2d: 2-7 [1, 384, 25, 25] 663,936
│ └─ReLU: 2-8 [1, 384, 25, 25] --
│ └─Conv2d: 2-9 [1, 256, 25, 25] 884,992
│ └─ReLU: 2-10 [1, 256, 25, 25] --
│ └─Conv2d: 2-11 [1, 256, 25, 25] 590,080
│ └─ReLU: 2-12 [1, 256, 25, 25] --
│ └─MaxPool2d: 2-13 [1, 256, 12, 12] --
├─AdaptiveAvgPool2d: 1-2 [1, 256, 6, 6] --
├─Sequential: 1-3 [1, 1000] --
│ └─Dropout: 2-14 [1, 9216] --
│ └─Linear: 2-15 [1, 4096] 37,752,832
│ └─ReLU: 2-16 [1, 4096] --
│ └─Dropout: 2-17 [1, 4096] --
│ └─Linear: 2-18 [1, 4096] 16,781,312
│ └─ReLU: 2-19 [1, 4096] --
│ └─Linear: 2-20 [1, 1000] 4,097,000
==========================================================================
Total params: 61,100,840
Trainable params: 61,100,840
Non-trainable params: 0
Total mult-adds (G): 2.44
==========================================================================
Input size (MB): 2.08
Forward/backward pass size (MB): 13.98
Params size (MB): 244.40
Estimated Total Size (MB): 260.46
==========================================================================モデルの一覧
| モデル名 | 関数名 | パラメータ数 | Top-1 エラー率 | Top-5 エラー率 |
|---|---|---|---|---|
| AlexNet | alexnet() | 61100840 | 43.45 | 20.91 |
参考
- alexnet-pytorch/model.py at master · dansuh17/alexnet-pytorch: 論文に従った AlexNet の Pytroch 実装
- 深層学習論文の読解(AlexNet) – Qiita
コメント