
概要
torch.utils.data,DataLoader
DataLoader は、Dataset からサンプルを取得して、ミニバッチを作成するクラスです。基本的には、サンプルを取得する Dataset とバッチサイズを指定して作成します。DataLoader は、iterate するとミニバッチを返すようになっています。
DataLoader(dataset, batch_size=1, shuffle=False, sampler=None,
batch_sampler=None, num_workers=0, collate_fn=None,
pin_memory=False, drop_last=False, timeout=0,
worker_init_fn=None)- dataset: データセット
- batch_size: バッチサイズ
- shuffle: シャッフルするかどうか
- sampler: サンプラー
- batch_sampler: サンプラー
- num_workers: 並列実行数
- collate_fn:ミニバッチ作成前に使用されるコールバック関数
- pin_memory: pinned memory を使用するかどうか
- drop_last: 最後の余りのミニバッチは切り捨てるかどうか
- timeout: ミニバッチを作成する時間制限
- worker_init_fn: ミニバッチ作成前に呼ばれるコールバック関数
Dataset – データセット
Dataset は、データセットを表すクラスで、サンプルを要求されたときに返す処理を定義します。Dataset は次の2種類があります。
- map-style Dataset: キー (通常はインデックス) を渡して、それに対応するデータを返す Dataset です。キーに対応するサンプルを返す
__getitem__()及びデータセットのサンプル数を返す__len__()が実装されている必要があります。 - iterable-style Dataset: 逐次データを返す iterable な Dataset です。
__iter__()が実装されている必要があります。
map-style Dataset を自作する
map-style Dataset を自作する場合、Dataset を継承したクラスを作成し、キーが渡されたときにそれに対応するサンプルを返す __getitem__() 及びデータセットのサンプル数を返す __len__() を実装します。
from torch.utils.data import Dataset
class ImageFolder(Dataset):
def __getitem__(self, index):
# 1つのサンプルを返す処理を書く
def __len__(self):
# データセットのサンプル数を返す処理を書く指定されたディレクトリから画像を読み込んで返す Dataset を作成してみます。
def _get_img_paths(img_dir):
img_extensions = [".jpg", ".jpeg", ".png", ".bmp"]
img_paths = [p for p in Path(img_dir).iterdir() if p.suffix in img_extensions]
return img_paths
class ImageFolder(data.Dataset):
def __init__(self, img_dir, transform=None):
# 画像ファイルのパス一覧を取得する。
self.img_paths = _get_img_paths(img_dir)
self.transform = transform
def __getitem__(self, index):
# インデックスに対応するファイルパスを取得する。
path = self.img_paths[index]
# 画像を読み込む。
img = Image.open(path)
# Transforms で変換する。
if transform is not None:
img = self.transform(img)
return img
def __len__(self):
# ディレクトリ内の画像枚数を返す。
return len(self.img_paths)これを使って data ディレクトリに画像ファイルがあるとき、以下のようにサンプルを取得できます。
transform = transforms.Compose(
[transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor()]
)
dataset = ImageFolder("data", transform)
# データを取得する。
for i in range(len(dataset)):
img = dataset[i]
print(type(img), img.shape)<class 'torch.Tensor'> torch.Size([3, 224, 224]) <class 'torch.Tensor'> torch.Size([3, 224, 224]) <class 'torch.Tensor'> torch.Size([3, 224, 224]) <class 'torch.Tensor'> torch.Size([3, 224, 224]) <class 'torch.Tensor'> torch.Size([3, 224, 224])
import numpy as np
from torch.utils import data as data
class MyDataset(data.Dataset):
def __init__(self, n):
self.data = np.random.rand(n, 100, 100, 3)
self.labels = np.arange(n)
def __getitem__(self, index):
return self.data[index], self.labels[index]
def __len__(self):
return len(self.data)
dataset = MyDataset(10)batchsize
DataLoader が返すミニバッチのサイズを設定します。
batchsize=None とした場合、ミニバッチの代わりにサンプル1つを返します。この場合、バッチ次元はありません。
batchsize に1以上の整数を指定した場合、複数のサンプルから作成したミニバッチを返します。
print("batchsize=None")
dataloader = data.DataLoader(dataset, batch_size=None)
X, y = next(iter(dataloader))
print(X.shape, y)
print("batchsize=int")
dataloader = data.DataLoader(dataset, batch_size=3)
X, y = next(iter(dataloader))
print(X.shape, y.shape)batchsize=None torch.Size([100, 100, 3]) tensor(0) batchsize=int torch.Size([3, 100, 100, 3]) torch.Size([3])
shuffle – シャッフルするかどうか
shuffle=True の場合、シャッフルした順番で返します。
print("shuffle=False")
dataloader = data.DataLoader(dataset, batch_size=5)
for X, y in dataloader:
print(y, end=" ")
print("\nshuffle=True")
dataloader = data.DataLoader(dataset, batch_size=5, shuffle=True)
for X, y in dataloader:
print(y, end=" ")shuffle=False tensor([0, 1, 2, 3, 4]) tensor([5, 6, 7, 8, 9]) shuffle=True tensor([7, 0, 5, 4, 1]) tensor([2, 8, 9, 6, 3])
sampler – 次に読み込むサンプルのキーを返す
Sampler は、map-style データセットの場合に、サンプルのキーを返す iterable なクラスで、データセットから読み込む順序を規定します。デフォルトの Sampler がいくつか用意されており、例えば、DataLoader() で shuffle=False を指定した場合、データセットから順番に読み込む SequentialSampler、shuffle=True を指定した場合、重複なしでランダムな順番で読み込む RandomSampler が使用されます。
大抵の場合、上記2つで事足りるので自作する必要性はあまりないですが、torch.utils.data.SequentialSampler の実装を見てみます。
class SequentialSampler(data.Sampler):
def __init__(self, dataset):
self.dataset = dataset
def __iter__(self):
return iter(range(len(self.dataset)))
sampler = SequentialSampler(dataset)
for i in sampler: # iterate すると、読み込むサンプルのキーを返す
print(i, end=" ")0 1 2 3 4 5 6 7 8 9
BatchSampler – ミニバッチ作成に使用するサンプルのキー一覧を返す
BatchSampler は、map-style データセットの場合に、ミニバッチに使用するサンプルのキー一覧を返す iterable なクラスです。torch.utils.data.BatchSampler の実装を見てみます。
class BatchSampler(data.Sampler):
def __init__(self, sampler, batch_size):
self.sampler = sampler
self.batch_size = batch_size
def __iter__(self):
batch = []
for idx in self.sampler:
batch.append(idx)
if len(batch) == self.batch_size:
yield batch
batch = []
if len(batch) > 0:
yield batch
batch_sampler = BatchSampler(sampler, 3)
for batch_indices in batch_sampler:
print(batch_indices)[0, 1, 2] [3, 4, 5] [6, 7, 8] [9]
num_workers – ミニバッチを作成する際の並列実行数
num_workers でミニバッチを作成する際の並列実行数を指定できます。
最大で CPU の論理スレッド数分の高速化が期待できます。
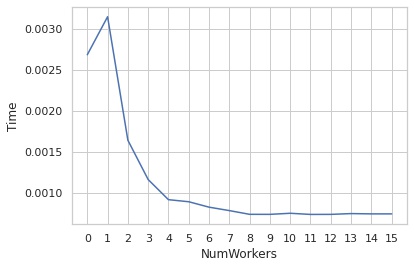
以下は、num_workers を変化させたとき、読み込み1枚あたりにかかる時間をグラフ化したものです。
使用した Core i7-6700K は、論理スレッドが8なので、8までは増やすほど読み込みが高速化することが確認できました。
- サンプル数: 12894
- バッチサイズ: 128
- CPU: Intel(R) Core(TM) i7-6700K CPU @ 4.00GHz
collate_fn – サンプルのリストを集計してミニバッチを作成する関数
collate_fn は Dataset から取得した複数のサンプルを結合して、1つのミニバッチを作成する処理を行う関数です。
デフォルトでは、default_collate が使用されます。default_collate() では渡される batch の各要素が以下の場合に対応しています。
- Tensor
- ndarray (dtype = “S”, “a”, “U”, “O” を除く)
- float
- int
- str
- bytes
- Mapping (dict など)
- namedtuple
- Sequence (list, tuple など)
default_collate の実装を見ています。
import collections
import re
import numpy as np
import torch
np_str_obj_array_pattern = re.compile(r"[SaUO]")
default_collate_err_msg_format = (
"default_collate: batch must contain tensors, numpy arrays, numbers, "
"dicts or lists; found {}"
)
def default_collate(batch):
elem = batch[0]
elem_type = type(elem)
print(f"elem_type.__name__: {elem_type.__name__}")
if isinstance(elem, torch.Tensor):
# Tensor の場合はそのまま結合
return torch.stack(batch, 0)
elif (
elem_type.__module__ == "numpy"
and elem_type.__name__ != "str_"
and elem_type.__name__ != "string_"
):
if elem_type.__name__ == "ndarray" or elem_type.__name__ == "memmap":
# numpy 配列の場合
if np_str_obj_array_pattern.search(elem.dtype.str) is not None:
raise TypeError(default_collate_err_msg_format.format(elem.dtype))
# スカラー以外の場合、テンソルに変換して、default_collate() にもう一度渡す。
return default_collate([torch.as_tensor(b) for b in batch])
elif elem.shape == ():
# スカラーの場合、そのままテンソルにする。
return torch.as_tensor(batch)
elif isinstance(elem, float):
# float の場合、そのままテンソルにする。
return torch.tensor(batch, dtype=torch.float64)
elif isinstance(elem, int):
# int の場合、そのままテンソルにする。
return torch.tensor(batch)
elif isinstance(elem, (str, bytes)):
# str, bytes の場合、そのまま返す。
return batch
elif isinstance(elem, collections.abc.Mapping):
# Mapping の場合 (dict など)、キーごとにテンソル化する。
return {key: default_collate([d[key] for d in batch]) for key in elem}
elif isinstance(elem, tuple) and hasattr(elem, "_fields"):
# namedtuple の場合
return elem_type(*(default_collate(samples) for samples in zip(*batch)))
elif isinstance(elem, collections.abc.Sequence):
# sequence の場合
it = iter(batch)
elem_size = len(next(it))
if not all(len(elem) == elem_size for elem in it):
raise RuntimeError("each element in list of batch should be of equal size")
transposed = zip(*batch)
return [default_collate(samples) for samples in transposed]
raise TypeError(default_collate_err_msg_format.format(elem_type))各要素が numpy 配列の場合
# 各要素が (10, 10) の numpy 配列
batch = [np.random.rand(10, 10) for i in range(5)]
output = default_collate(batch)
print(f"output.shape: {output.shape}, output.dtype: {output.dtype}")
# 各要素が () の numpy 配列 (スカラー)
batch = [np.array(5) for i in range(5)]
output = default_collate(batch)
print(f"output.shape: {output.shape}, output.dtype: {output.dtype}")elem_type.__name__: ndarray elem_type.__name__: Tensor output.shape: torch.Size([5, 10, 10]), output.dtype: torch.float64 elem_type.__name__: ndarray elem_type.__name__: Tensor output.shape: torch.Size([5]), output.dtype: torch.int64
int, float の場合
# 各要素が int
batch = [1 for i in range(5)]
output = default_collate(batch)
print(f"output.shape: {output.shape}, output.dtype: {output.dtype}")
# 各要素が () の numpy 配列 (スカラー)
batch = [1.1 for i in range(5)]
output = default_collate(batch)
print(f"output.shape: {output.shape}, output.dtype: {output.dtype}")elem_type.__name__: int output.shape: torch.Size([5]), output.dtype: torch.int64 elem_type.__name__: float output.shape: torch.Size([5]), output.dtype: torch.float64
str の場合
# 各要素が str
batch = ["hoge" for i in range(5)]
output = default_collate(batch)
print(output)elem_type.__name__: str ['hoge', 'hoge', 'hoge', 'hoge', 'hoge']
Mapping の場合 (dict など)
# 各要素が str
batch = [{"A": np.random.rand(10, 10), "B": "hoge", "C": 1} for i in range(5)]
output = default_collate(batch)
for key, value in output.items():
if isinstance(value, list):
print(f"key: {key}, len(value): {len(value)}, type(value[0]): {type(value[0])}")
else:
print(f"key: {key}, value.shape: {value.shape}, value.dtype: {value.dtype}")elem_type.__name__: dict elem_type.__name__: ndarray elem_type.__name__: Tensor elem_type.__name__: str elem_type.__name__: int key: A, value.shape: torch.Size([5, 10, 10]), value.dtype: torch.float64 key: B, len(value): 5, type(value[0]): <class 'str'> key: C, value.shape: torch.Size([5]), value.dtype: torch.int64
namedtuple の場合
from collections import namedtuple
Sample = namedtuple("sample", ["A", "B", "C"])
# 各要素が str
batch = [Sample(np.random.rand(10, 10), "hoge", 1) for i in range(5)]
output = default_collate(batch)
for key, value in output._asdict().items():
if isinstance(value, torch.Tensor):
print(f"key: {key}, value.shape: {value.shape}, value.dtype: {value.dtype}")
else:
print(f"key: {key}, len(value): {len(value)}, type(value[0]): {type(value[0])}")elem_type.__name__: sample elem_type.__name__: ndarray elem_type.__name__: Tensor elem_type.__name__: str elem_type.__name__: int key: A, value.shape: torch.Size([5, 10, 10]), value.dtype: torch.float64 key: B, len(value): 5, type(value[0]): <class 'str'> key: C, value.shape: torch.Size([5]), value.dtype: torch.int64
Sequence の場合
# 各要素が list
batch = [["hoge", 2, np.random.rand(2, 2)] for i in range(5)]
output = default_collate(batch)
for value in output:
if isinstance(value, torch.Tensor):
print(f"value.shape: {value.shape}, value.dtype: {value.dtype}")
else:
print(f"len(value): {len(value)}, type(value[0]): {type(value[0])}")
# 各要素が tuple
batch = [("hoge", 2, np.random.rand(2, 2)) for i in range(5)]
output = default_collate(batch)
for value in output:
if isinstance(value, torch.Tensor):
print(f"value.shape: {value.shape}, value.dtype: {value.dtype}")
else:
print(f"len(value): {len(value)}, type(value[0]): {type(value[0])}")elem_type.__name__: list elem_type.__name__: str elem_type.__name__: int elem_type.__name__: ndarray elem_type.__name__: Tensor len(value): 5, type(value[0]): <class 'str'> value.shape: torch.Size([5]), value.dtype: torch.int64 value.shape: torch.Size([5, 2, 2]), value.dtype: torch.float64 elem_type.__name__: tuple elem_type.__name__: str elem_type.__name__: int elem_type.__name__: ndarray elem_type.__name__: Tensor len(value): 5, type(value[0]): <class 'str'> value.shape: torch.Size([5]), value.dtype: torch.int64 value.shape: torch.Size([5, 2, 2]), value.dtype: torch.float64
drop_last – 最後の余りのミニバッチは切り捨てる
drop_last=True を指定した場合、端数となってしまった最後のミニバッチは切り捨てます。
例えば、500 サンプルをバッチサイズ 128 で読み込んだ場合、128, 128, 128, 116 と最後だけ端数となってしまいますが、
drop_last=True の場合はこの最後の 116 は切り捨てるようになります。
print(f"number of samples: {len(dataset)}")
dataloader = data.DataLoader(dataset, batch_size=128, drop_last=False)
print("drop_last=False")
for X, y in dataloader:
print(X.shape, y.shape)
dataloader = data.DataLoader(dataset, batch_size=128, drop_last=True)
print("drop_last=True")
for X, y in dataloader:
print(X.shape, y.shape)number of samples: 501 drop_last=False torch.Size([128, 3, 224, 224]) torch.Size([128]) torch.Size([128, 3, 224, 224]) torch.Size([128]) torch.Size([128, 3, 224, 224]) torch.Size([128]) torch.Size([117, 3, 224, 224]) torch.Size([117]) drop_last=True torch.Size([128, 3, 224, 224]) torch.Size([128]) torch.Size([128, 3, 224, 224]) torch.Size([128]) torch.Size([128, 3, 224, 224]) torch.Size([128])
コメント