
概要
ディープラーニングの画像認識モデルである ResNet を解説し、Pytorch の実装例を紹介します。
ResNet
ResNet は、画像認識のコンテスト ILSVRC 2015 にて、top5 error rate で3.57%を記録し、優勝した CNN ネットワークモデルです。下記、2論文に基づいて解説します。
ResNet が考案された背景
CNN が画像認識分野でブレイクスルーを起こしてから、層を深くすることで精度向上が図られてきましたが、一方、層を深くした影響で、勾配消失問題、劣化問題 (degradation problem) が発生し、学習が難しくなる問題が生じました。勾配消失問題は様々なアプローチで取り組まれ解決が図られましたが、もうひとつの劣化問題に着目し、深い層でも学習が行えるネットワークアーキテクチャとして ResNet が考案されました。
劣化問題
劣化問題 (degradation problem) とは、層が深いモデルの学習において、訓練誤差の改善が層が浅いモデルより早い段階で頭打ちになる現象です。

層が浅いモデルとそのモデルに何層か追加した層が深いモデルの2つがあった場合、層が深いモデルは浅いモデルより訓練誤差が同等か改善するはずです。 なぜなら、層が深いモデルは関数 $F$ は層が浅いモデルと同じに、追加した関数 $G$ は $G(x) = x$ と恒等写像となるように学習すれば、浅いモデルと同じ関数を学習できるからです。
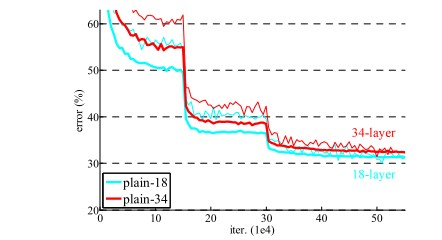
上図は18層のモデル及び34層のモデルの学習時の訓練誤差、テスト誤差の推移です。(細線が訓練誤差、太線がテスト誤差) 18層より34層のモデルのほうが、訓練誤差の改善が期待しますが、実際は層を深くした34層のモデルのほうが訓練誤差が劣化しています。訓練誤差の問題のため、過学習が原因ではありません。
Residual Network

図は左が従来のネットワーク (plain network)、右がこれから紹介する residual network の一部を表しています。
$F(\boldsymbol{x}) = \boldsymbol{x}$ と恒等写像を学習するのが最適であった場合を考えます。 左では、非線形関数 $F$ のパラメータ $\boldsymbol{w}$ を調整し、恒等写像を学習する必要がありますが、これが難しいため劣化問題が起こるのではないかと論文では推察しています。 そのため、右のように Shortcut Connection または Identity Mapping という迂回路を追加し、$F(\boldsymbol{x}) + \boldsymbol{x}$ を出力とするように変更しました。 こうした場合、恒等写像を学習するには $F(\boldsymbol{x}) = \boldsymbol{0}$、つまりパラメータを $\boldsymbol{w} = \boldsymbol{0}$ になるよう学習すればよいので、前者に比べ学習がより簡単になります。 図の右の何層かの畳み込み層と shortcut connection から成るブロックを residual block といいます。この residual block を複数重ねたネットワークが Residual Network (ResNet) です。
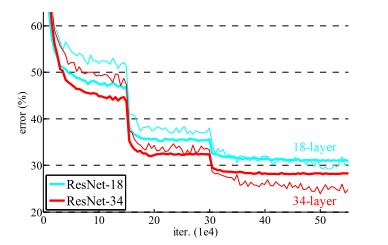
上図は18層のモデル及び34層のモデルの学習時の訓練誤差、テスト誤差の推移です。(細線が訓練誤差、太線がテスト誤差) 18層より34層のモデルのほうが、訓練誤差、テスト誤差が改善していることが確認できます。
ResNet
ネットワーク構成
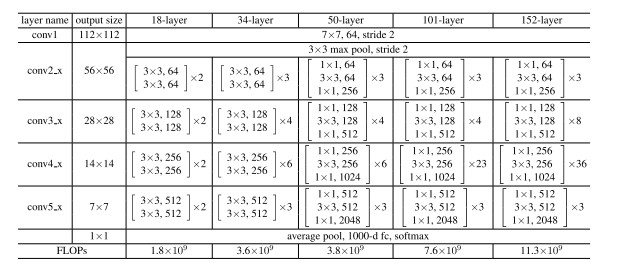
ResNet-18, ResNet-34, ResNet-50, ResNet-101, ResNet-152 の5種類が提案されています。

いずれも上記の構成になっており、conv2_x, conv3_x, conv4_x, conv5_x の部分は residual block を以下で示すパラメータに従い、繰り返したモデルになっています。
shortcut connection
residual block の最後で $F(x)$ と shortcut connection を通ってきた値 $x$ を足し合わせるため、形状を一致させる必要があります。 $F(x)$ と $x$ の形状が異なる場合は、ゼロパディングまたは線形変換 $W_s \boldsymbol{x}$ で形状を一致させます。
論文では、ResNet-34 に対して、以下の3パターンの実験を行いました。
- A: $F(x)$ と $x$ の形状が異なる場合のみ、ゼロパディングを行います。
- B: $F(x)$ と $x$ の形状が異なる場合のみ、線形変換 $W_s x$ を行い、同じ場合は $x$ とします。
- C: 常に線形変換 $W_s x$ を行います。
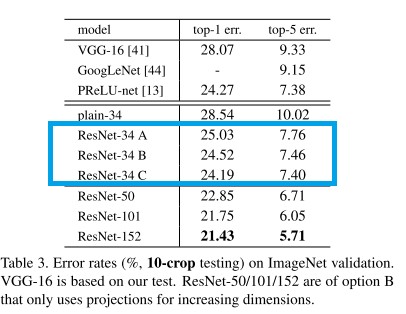
結果は A < B < C の順に性能がよいことがわかりました。B と C は僅差であり、計算量は C のほうが多くなるので、論文では B を採用しました。
residual block
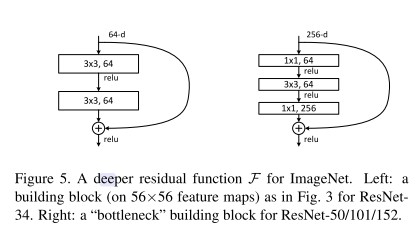
residual block の $F(x)$ は通常2から3層の畳み込み層で構成されるが、それ以上でもよいです。論文では、以下の2パターンを採用しました。
- Building Block: 3×3 の2つの畳み込み層で構成。ResNet-18、ResNet-34 の residual block として使用。
- Bottleneck Building Block: 1×1、3×3、1×1 の3つの畳み込み層で構成。ResNet-50、ResNet-101、ResNet-152 の residual block として使用。
torchvision の ResNet の実装
torchvision.models.resnet の ResNet の実装について解説します。
Building Block の実装
BasicBlock クラスで Building Block を定義しています。順伝搬時の処理は以下のようになっています。
- Conv2D (kernel_size=3, padding=1, stride=1 or 2)
- BatchNorm2d
- ReLU
- Conv2D (kernel_size=3, padding=1, stride=1)
- BatchNorm2d
- 形状が入力と異なる場合は、1×1 の畳み込み層で線形変換を行います。
- shortcut connection と結合します。
- ReLU
各 Residual Blocks の最初の Residual Block では、入力と出力のチャンネル数または大きさが異なるため (in_channels != channels * self.expansion)、shortcut connection の出力を足し合わせる際に形状を一致させる必要があります。その場合、1×1 の畳み込みを利用して、線形変換を行い、形状を一致させます。
import torch
import torch.nn as nn
def conv3x3(in_channels, out_channels, stride=1):
return nn.Conv2d(
in_channels,
out_channels,
kernel_size=3,
stride=stride,
padding=1,
bias=False,
)
def conv1x1(in_channels, out_channels, stride=1):
return nn.Conv2d(
in_channels, out_channels, kernel_size=1, stride=stride, bias=False
)
class BasicBlock(nn.Module):
expansion = 1 # 出力のチャンネル数を入力のチャンネル数の何倍に拡大するか
def __init__(
self,
in_channels,
channels,
stride=1
):
super().__init__()
self.conv1 = conv3x3(in_channels, channels, stride)
self.bn1 = nn.BatchNorm2d(channels)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(channels, channels)
self.bn2 = nn.BatchNorm2d(channels)
# 入力と出力のチャンネル数が異なる場合、x をダウンサンプリングする。
if in_channels != channels * self.expansion:
self.shortcut = nn.Sequential(
conv1x1(in_channels, channels * self.expansion, stride),
nn.BatchNorm2d(channels * self.expansion),
)
else:
self.shortcut = nn.Sequential()
def forward(self, x):
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out += self.shortcut(x)
out = self.relu(out)
return outBottleneck Block の実装
Bottleneck クラスで Bottleneck Block を定義しています。順伝搬時の処理は以下のようになっています。
- Conv2D (kernel_size=1, padding=0, stride=1)
- BatchNorm2d
- ReLU
- Conv2D (kernel_size=3, padding=1, stride=1 or 2)
- BatchNorm2d
- ReLU
- Conv2D (kernel_size=1, padding=0, stride=1)
- BatchNorm2d
- 形状が入力と異なる場合は、1×1 の畳み込み層で線形変換を行います。
- shortcut connection と結合します。
- ReLU
Pytorch の実装は ResNet v1.5 というもので、論文の ResNet と次の点が異なります。論文ではダウンサンプリングを行う場合に1つ目の畳み込み層で行っていましたが、v1.5 では2つ目の畳み込み層で行います。この変更により、Top1 Accuracy が0.5%程度高くなり、5% 程度計算量が増えたようです。
class Bottleneck(nn.Module):
expansion = 4 # 出力のチャンネル数を入力のチャンネル数の何倍に拡大するか
def __init__(self, in_channels, channels, stride=1):
super().__init__()
self.conv1 = conv1x1(in_channels, channels)
self.bn1 = nn.BatchNorm2d(channels)
self.conv2 = conv3x3(channels, channels, stride)
self.bn2 = nn.BatchNorm2d(channels)
self.conv3 = conv1x1(channels, channels * self.expansion)
self.bn3 = nn.BatchNorm2d(channels * self.expansion)
self.relu = nn.ReLU(inplace=True)
# 入力と出力のチャンネル数が異なる場合、x をダウンサンプリングする。
if in_channels != channels * self.expansion:
self.shortcut = nn.Sequential(
conv1x1(in_channels, channels * self.expansion, stride),
nn.BatchNorm2d(channels * self.expansion),
)
else:
self.shortcut = nn.Sequential()
def forward(self, x):
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out += self.shortcut(x)
out = self.relu(out)
return outResNet を定義する
ResNet クラスで ResNet 全体のモデルを作成します。
- Conv2D (out_channels=64, kernel_size=7, padding=2, stride=3)
- BatchNorm2d
- MaxPool2d (kernel_size=3, stride=2, padding=1)
- Residual Blocks (in_channels=64)
- Residual Blocks (in_channels=128)
- Residual Blocks (in_channels=256)
- Residual Blocks (in_channels=512)
- Global Average Pooling
- Linear (out_channels=num_classes)
ただし、2、3、4 個目の Residual Blocks では、最初の畳み込み層で
stride=2で畳み込みを行い、ダウンサンプリングを行います。1つ目の Residual Block は、直前で Max Pooling でダウンサンプリングを行っているので、畳み込みによるダウンサンプリングは不要です。畳み込み層の初期化は He initialization (torch.nn.init.kaimingnormal) を使用し、Batch Normalization 層の初期化は重み1、バイアス0で初期化します。
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=1000):
super().__init__()
self.in_channels = 64
self.conv1 = nn.Conv2d(
3, self.in_channels, kernel_size=7, stride=2, padding=3, bias=False
)
self.bn1 = nn.BatchNorm2d(self.in_channels)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0], stride=1)
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
# 重みを初期化する。
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode="fan_out", nonlinearity="relu")
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def _make_layer(self, block, channels, blocks, stride):
layers = []
# 最初の Residual Block
layers.append(block(self.in_channels, channels, stride))
# 残りの Residual Block
self.in_channels = channels * block.expansion
for _ in range(1, blocks):
layers.append(block(self.in_channels, channels))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
各 ResNet のモデルを作成する関数を作ります。第2引数は4つの Residual Blocks の Residual Block を繰り返す回数を表しています。
def resnet18():
return ResNet(BasicBlock, [2, 2, 2, 2])
def resnet34():
return ResNet(BasicBlock, [3, 4, 6, 3])
def resnet50():
return ResNet(Bottleneck, [3, 4, 6, 3])
def resnet101():
return ResNet(Bottleneck, [3, 4, 23, 3])
def resnet152():
return ResNet(Bottleneck, [3, 8, 36, 3])torchinfo で表示する
torchinfo で各層のパラメータや出力の形状を確認します。
torchinfo は pip install torchinfo でインストールできます。
from torchinfo import summary
model = resnet18()
summary(
model,
input_size=(1, 3, 224, 224),
col_names=["output_size", "num_params"],
)==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
ResNet [1, 1000] --
├─Conv2d: 1-1 [1, 64, 112, 112] 9,408
├─BatchNorm2d: 1-2 [1, 64, 112, 112] 128
├─ReLU: 1-3 [1, 64, 112, 112] --
├─MaxPool2d: 1-4 [1, 64, 56, 56] --
├─Sequential: 1-5 [1, 64, 56, 56] --
│ └─BasicBlock: 2-1 [1, 64, 56, 56] --
│ │ └─Conv2d: 3-1 [1, 64, 56, 56] 36,864
│ │ └─BatchNorm2d: 3-2 [1, 64, 56, 56] 128
│ │ └─ReLU: 3-3 [1, 64, 56, 56] --
│ │ └─Conv2d: 3-4 [1, 64, 56, 56] 36,864
│ │ └─BatchNorm2d: 3-5 [1, 64, 56, 56] 128
│ │ └─Sequential: 3-6 [1, 64, 56, 56] --
│ │ └─ReLU: 3-7 [1, 64, 56, 56] --
│ └─BasicBlock: 2-2 [1, 64, 56, 56] --
│ │ └─Conv2d: 3-8 [1, 64, 56, 56] 36,864
│ │ └─BatchNorm2d: 3-9 [1, 64, 56, 56] 128
│ │ └─ReLU: 3-10 [1, 64, 56, 56] --
│ │ └─Conv2d: 3-11 [1, 64, 56, 56] 36,864
│ │ └─BatchNorm2d: 3-12 [1, 64, 56, 56] 128
│ │ └─Sequential: 3-13 [1, 64, 56, 56] --
│ │ └─ReLU: 3-14 [1, 64, 56, 56] --
├─Sequential: 1-6 [1, 128, 28, 28] --
│ └─BasicBlock: 2-3 [1, 128, 28, 28] --
│ │ └─Conv2d: 3-15 [1, 128, 28, 28] 73,728
│ │ └─BatchNorm2d: 3-16 [1, 128, 28, 28] 256
│ │ └─ReLU: 3-17 [1, 128, 28, 28] --
│ │ └─Conv2d: 3-18 [1, 128, 28, 28] 147,456
│ │ └─BatchNorm2d: 3-19 [1, 128, 28, 28] 256
│ │ └─Sequential: 3-20 [1, 128, 28, 28] 8,448
│ │ └─ReLU: 3-21 [1, 128, 28, 28] --
│ └─BasicBlock: 2-4 [1, 128, 28, 28] --
│ │ └─Conv2d: 3-22 [1, 128, 28, 28] 147,456
│ │ └─BatchNorm2d: 3-23 [1, 128, 28, 28] 256
│ │ └─ReLU: 3-24 [1, 128, 28, 28] --
│ │ └─Conv2d: 3-25 [1, 128, 28, 28] 147,456
│ │ └─BatchNorm2d: 3-26 [1, 128, 28, 28] 256
│ │ └─Sequential: 3-27 [1, 128, 28, 28] --
│ │ └─ReLU: 3-28 [1, 128, 28, 28] --
├─Sequential: 1-7 [1, 256, 14, 14] --
│ └─BasicBlock: 2-5 [1, 256, 14, 14] --
│ │ └─Conv2d: 3-29 [1, 256, 14, 14] 294,912
│ │ └─BatchNorm2d: 3-30 [1, 256, 14, 14] 512
│ │ └─ReLU: 3-31 [1, 256, 14, 14] --
│ │ └─Conv2d: 3-32 [1, 256, 14, 14] 589,824
│ │ └─BatchNorm2d: 3-33 [1, 256, 14, 14] 512
│ │ └─Sequential: 3-34 [1, 256, 14, 14] 33,280
│ │ └─ReLU: 3-35 [1, 256, 14, 14] --
│ └─BasicBlock: 2-6 [1, 256, 14, 14] --
│ │ └─Conv2d: 3-36 [1, 256, 14, 14] 589,824
│ │ └─BatchNorm2d: 3-37 [1, 256, 14, 14] 512
│ │ └─ReLU: 3-38 [1, 256, 14, 14] --
│ │ └─Conv2d: 3-39 [1, 256, 14, 14] 589,824
│ │ └─BatchNorm2d: 3-40 [1, 256, 14, 14] 512
│ │ └─Sequential: 3-41 [1, 256, 14, 14] --
│ │ └─ReLU: 3-42 [1, 256, 14, 14] --
├─Sequential: 1-8 [1, 512, 7, 7] --
│ └─BasicBlock: 2-7 [1, 512, 7, 7] --
│ │ └─Conv2d: 3-43 [1, 512, 7, 7] 1,179,648
│ │ └─BatchNorm2d: 3-44 [1, 512, 7, 7] 1,024
│ │ └─ReLU: 3-45 [1, 512, 7, 7] --
│ │ └─Conv2d: 3-46 [1, 512, 7, 7] 2,359,296
│ │ └─BatchNorm2d: 3-47 [1, 512, 7, 7] 1,024
│ │ └─Sequential: 3-48 [1, 512, 7, 7] 132,096
│ │ └─ReLU: 3-49 [1, 512, 7, 7] --
│ └─BasicBlock: 2-8 [1, 512, 7, 7] --
│ │ └─Conv2d: 3-50 [1, 512, 7, 7] 2,359,296
│ │ └─BatchNorm2d: 3-51 [1, 512, 7, 7] 1,024
│ │ └─ReLU: 3-52 [1, 512, 7, 7] --
│ │ └─Conv2d: 3-53 [1, 512, 7, 7] 2,359,296
│ │ └─BatchNorm2d: 3-54 [1, 512, 7, 7] 1,024
│ │ └─Sequential: 3-55 [1, 512, 7, 7] --
│ │ └─ReLU: 3-56 [1, 512, 7, 7] --
├─AdaptiveAvgPool2d: 1-9 [1, 512, 1, 1] --
├─Linear: 1-10 [1, 1000] 513,000
==========================================================================================
Total params: 11,689,512
Trainable params: 11,689,512
Non-trainable params: 0
Total mult-adds (G): 1.81
==========================================================================================
Input size (MB): 0.60
Forward/backward pass size (MB): 39.75
Params size (MB): 46.76
Estimated Total Size (MB): 87.11
==========================================================================================ResNet のパラメータ数と精度
ResNet のパラメータ数と ImageNet のエラー率は次のようになっています。層が増えるほど精度は高くなりますが、パラメータ数は増加するため、計算量が増えます。
| モデル名 | 関数 | パラメータ数 | Top-1 エラー率 | Top-5 エラー率 |
|---|---|---|---|---|
| ResNet-18 | resnet18() | 11689512 | 30.24 | 10.92 |
| ResNet-34 | resnet34() | 21797672 | 26.7 | 8.58 |
| ResNet-50 | resnet50() | 25557032 | 23.85 | 7.13 |
| ResNet-101 | resnet101() | 44549160 | 22.63 | 6.44 |
| ResNet-152 | resnet152() | 60192808 | 21.69 | 5.94 |
| ResNeXt-50-32x4d | resnext50_32x4d() | 25028904 | 22.38 | 6.3 |
| ResNeXt-101-32x8d | resnext101_32x8d() | 88791336 | 20.69 | 5.47 |
| Wide ResNet-50-2 | wide_resnet50_2() | 68883240 | 21.49 | 5.91 |
| Wide ResNet-101-2 | wide_resnet101_2() | 126886696 | 21.16 | 5.72 |
参考
- ResNet50 v1.5 architecture
- Deep Residual Learning for Image Recognition
- Identity mappings in Deep Residual Networks
- Understanding and Implementing Architectures of ResNet and ResNeXt for state-of-the-art Image Classification: From Microsoft to Facebook [Part 1] | by Prakash Jay | Medium
- Residual Network(ResNet)の理解とチューニングのベストプラクティス – DeepAge
- ResNetの仕組み
- What exactly is the degradation problem that Deep Residual Networks try to alleviate? – Quora
- An Overview of ResNet and its Variants | by Vincent Feng | Towards Data Science
コメント
コメント一覧 (0件)
1) def __init__(self, in_channels, channels, stride=1):
print(in_channels, out_channes) <-誤字
2) tochinfoの情報と実装マッチしてますか?
3) 下記の実装はあってるのでしょうか?
# 入力と出力のチャンネル数が異なる場合、x をダウンサンプリングする。
if in_channels != channels * self.expansion:
コメントありがとうございます。
1.について
ご指摘ありがとうございます。修正しました。
2.について
torchinfo で表示しているのは resnet18 のパラメータになります。
Pytorch の resnet18 のパラメータを誤って記載していたので修正しました。
モデルの構造 (パラメータなど) は本家ののものと同一になります。
3. について
Building Block、Bottleneck Block いずれも最後の ReLU の直前で分岐させた結合を足し合わせます。その際、(C, H, W) の形状が一致している必要があるため、チャンネル数が異なる場合は 1×1 の畳み込みでチャンネルを一致させます。
実装としてはあっていると考えているのですが、もし疑問点がありましたら、確認します。