
概要
CNN の推論結果を解釈するには、入力画像に対する CNN の反応を可視化した顕著性マップ (saliency map) を見ることが有用です。 本記事では、Pytorch を使用して顕著性マップを作成する方法について解説します。
顕著性マップ (saliency map)
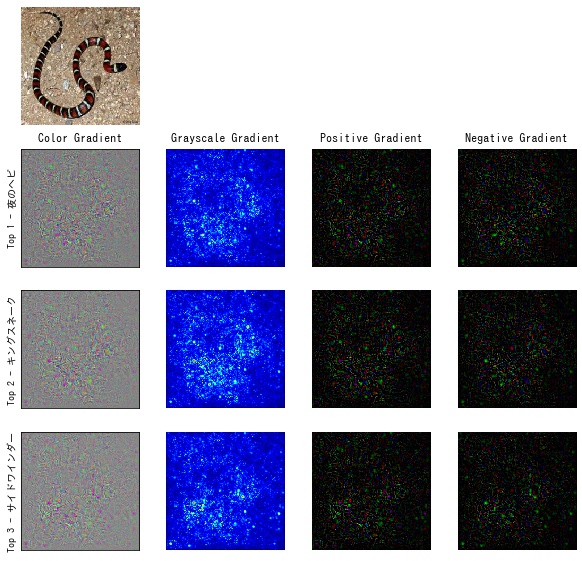
顕著性マップ (saliency map) は入力画像の各ピクセルに対して、CNN がどの程度反応したかを表すヒートマップです。モデルが強く反応した領域は、重要な情報を含んでいることを意味します。顕著性マップを作成することで、入力画像のどの領域が出力結果に影響したのかを視覚的に確認することができます。 顕著性マップ の作成方法は、Grad-CAM などいくつかの手法がありますが、本記事では通常の逆伝搬 (vanilla backpropagation) を利用した方法について、Pytorch の実装例を交えて解説します。
Pytorch による実装
必要なモジュールを import する
以下の外部ライブラリを使用します。ライブラリがない場合は、インストールしてください。
- OpenCV:
pip install opencv-contrib-python - matplotlib:
pip install matplotlib - NumPy:
pip install numpy - Pytorch:
pip install pytorch - torchvision:
pip install torchvision - opencv_transforms:
pip install opencv_transforms
import json
from collections import defaultdict
from inspect import isfunction
from pathlib import Path
import cv2
import matplotlib.pyplot as plt
import numpy as np
import torch
import torchvision
from opencv_transforms import transforms
from torch.nn import functional as F
from torch.utils.data import DataLoader, Dataset
from torchvision.datasets.utils import download_urlデバイスを選択する
使用するデバイスを表す device オブジェクトを返す関数を作成します。CUDA が利用可能かどうかは torch.cuda.is_available() で判定できます。use_gpu=True かつ CUDA が利用可能な場合は GPU デバイス、そうでない場合は CPU デバイスを返します。GPU デバイスを使用する場合、デフォルトでは、逆伝搬で計算した勾配の値が実行するたびに異なる現象が発生します。再現性を担保するために torch.backends.cudnn.deterministic = True に設定します。
def get_device(use_gpu):
if use_gpu and torch.cuda.is_available():
# これを有効にしないと、計算した勾配が毎回異なり、再現性が担保できない。
torch.backends.cudnn.deterministic = True
return torch.device("cuda")
else:
return torch.device("cpu")
# デバイスを選択する。
device = get_device(use_gpu=True)モデルを作成する
torchvision で利用可能なモデルの一覧を返す関数を作成します。モデルを作成する関数は models モジュール以下にあります。
dir()で models モジュール以下の属性名の一覧を取得する。getattr()で属性にする。- isfunction() でその属性が関数かどうかを判定する。関数の場合は、
dictにキーが関数名、値が関数という形で追加する。
def _get_avaable_models():
available_models = {}
for obj_name in dir(torchvision.models):
obj = getattr(torchvision.models, obj_name)
if isfunction(obj):
available_models[obj_name] = obj
return available_models指定した名前のモデルを作成する関数を作成します。
_get_avaable_models()で利用可能なモデルの一覧を取得する。available_models[name]で名前nameのモデルを作成する関数を取得する。- 学習済みモデルを使用するので、
pretrained=Trueを指定してモデルを作成する。 nn.Module.to()でモデルを使用するデバイスに転送する。nn.Module.eval()でモデルを推論モードに設定する。
今回、モデルは AlexNet を使用します。
def get_model(name, device):
available_models = _get_avaable_models()
if name not in available_models:
raise ValueError(f"{name} という名前のモデルは torchvision に存在しません。")
model_fn = available_models[name]
model = model_fn(pretrained=True).to(device)
model.eval()
return model
# モデルを作成する。
model = get_model("alexnet", device)DataLoader を作成する
まず、ディレクトリ内から指定した拡張子のファイルを探し、そのパスの一覧を返す関数を作成します。
def _get_img_paths(img_dir):
img_dir = Path(img_dir)
img_extensions = [".jpg", ".jpeg", ".png", ".bmp"]
img_paths = [str(p) for p in img_dir.iterdir() if p.suffix in img_extensions]
img_paths.sort()
return img_paths次に指定したディレクトリから画像を読み込む Dataset を作成します。 今回、ImageNet で学習済みのモデルを使用するため、そのモデルを学習したときと同じ以下の前処理を行う必要があります。
(224, 224)にリサイズする。- RGB の値を平均
[0.485, 0.456, 0.406]、分散[0.229, 0.224, 0.225]で標準化する。
init()
_get_img_paths(img_dir)で指定したディレクトリにある画像ファイルのパス一覧を取得する。- numpy 配列を Tensor に変換する ToTensor と標準化する Normalize を Compose で結合し、Transformer を作成する。
getitem(self, index)
self.img_paths[index]でインデックスindexのファイルパスを取得する。cv2.imread(path)で画像ファイルを読み込む。- OpenCV のチャンネル順は BGR、学習済みのモデルの入力画像のチャンネル順は RGB のため、
cv2.cvtColor(raw_img, cv2.COLOR_BGR2RGB)でチャンネル順を BGR から RGB にする。 cv2.resize(raw_img, ImageFolder.IMAGENET_SIZE)でリサイズする。self.transform(raw_img)で numpy 配列のテンソル化及び標準化を行う。- 標準化前の画像、標準化後の画像、ファイルパスを返す。
class ImageFolder(Dataset):
IMAGENET_SIZE = (224, 224)
IMAGENET_MEAN = [0.485, 0.456, 0.406]
IMAGENET_STD = [0.229, 0.224, 0.225]
def __init__(self, img_dir):
# 画像ファイルのパス一覧を取得する。
self.img_paths = _get_img_paths(img_dir)
# Transformer を作成する。
self.transform = transforms.Compose(
[
transforms.ToTensor(),
transforms.Normalize(
mean=ImageFolder.IMAGENET_MEAN, std=ImageFolder.IMAGENET_STD
),
]
)
def __getitem__(self, index):
path = self.img_paths[index]
# 画像を読み込む。
raw_img = cv2.imread(path)
# チャンネル順を BGR から RGB に変換する。
raw_img = cv2.cvtColor(raw_img, cv2.COLOR_BGR2RGB)
# リサイズする。
raw_img = cv2.resize(raw_img, ImageFolder.IMAGENET_SIZE)
# Transformer で変換する。
img = self.transform(raw_img)
sample = {"raw_image": raw_img, "image": img, "path": path}
return sample
def __len__(self):
return len(self.img_paths)
# Dataset を作成する。
dataset = ImageFolder("data")先程作成した Dataset オブジェクトからミニバッチを生成する DataLoader を作成します。
# DataLoader を作成する。
dataloader = DataLoader(dataset, batch_size=4)ImageNet の日本語のクラス名を取得する関数を作成します。
- クラス一覧を記載したファイルが存在しない場合、download_url() でダウンロードする。
- クラス一覧を記載した json ファイルを読み込む。
def get_classes():
if not Path("data/imagenet_class_index.json").exists():
# ファイルが存在しない場合はダウンロードする。
download_url("https://git.io/JebAs", "data", "imagenet_class_index.json")
# クラス一覧を読み込む。
with open("data/imagenet_class_index.json") as f:
data = json.load(f)
class_names = [x["ja"] for x in data]
return class_names
# クラス名一覧を取得する。
class_names = get_classes()Vanilla Backpropagation を計算する処理
先にコード全体を記載してから、解説します。
def to_onehot(y, n_classes):
# (N,) tensor to (N, NumClasses) tensor.
return torch.eye(n_classes)[y]
class VanillaBackprop:
def __init__(self, model):
self.model = model
self.device = next(model.parameters()).device
def forward(self, inputs):
inputs = inputs.to(self.device).requires_grad_()
# 勾配を初期化する。
self.model.zero_grad()
# 順伝搬を行う。
logits = self.model(inputs)
# softmax を適用する。
probs = F.softmax(logits, dim=1)
# 確率が大きい順にソートし、対応するクラス ID の一覧を返す。
class_ids = probs.sort(dim=1, descending=True)[1]
self.inputs = inputs
self.logits = logits
return class_ids
def backward(self, class_ids):
# 逆伝搬の入力を作成する。
onehot = to_onehot(class_ids, n_classes=self.logits.size(1)).to(self.device)
# 逆伝搬を行う。
self.logits.backward(gradient=onehot, retain_graph=True)
def generate(self):
# 入力層の勾配を取得する。
gradients = self.inputs.grad.clone()
# 入力層の勾配を初期化する。
self.inputs.grad.zero_()
return gradients順伝搬
- 入力画像
inputsをto()で使用するデバイスに転送する。入力画像は学習するパラメータを持たないので、デフォルトでは勾配の計算は行われい。そのため、requiresgrad() で勾配の計算を行うように設定する。 - zero_grad() で勾配を初期化する。
self.model(inputs)で順伝搬を行う。- モデルには出力層の softmax は含まれていないので、
F.softmax(logits, dim=1)で softmax を計算する。 class_ids = probs.sort(dim=1, descending=True)[1]で確率が大きい順にソートし、対応するクラス ID の一覧を返す。
逆伝搬
- 指定したクラス ID の箇所を1、それ以外の箇所を0とした逆伝搬の入力を作成する。
to()で使用するデバイスに転送する。logits.backward(gradient=onehot, retain_graph=True)で逆伝搬を行う。逆伝搬後も勾配の情報は保持しておきたいので、retain_graph=Trueを指定する。
勾配を取得する
self.inputs.gradで入力画像の勾配を取得する。- clone() でディープコピーする。
- モデルの入力画像の勾配は、
self.inputs.grad.zero_()で初期化する。
テンソルを画像化する
テンソルを画像に変換します。
normalize(x)でテンソルを $[0, 1]$ に正規化する。x.cpu().numpy()でテンソルを numpy 配列に変換する。transpose(0, 2, 3, 1)で軸を(B, C, H, W)から(B, H, W, C)に並び替える。- $[0, 1]$ に正規化されているので、255 を乗算し、
astype(np.uint8)でキャストすることで、[0, 255] の非負の整数に変換する。 x.shape[3] == 1、つまり、グレースケール画像の場合、x.squeeze(axis=3)で(B, H, W, 1)を(B, H, W)に変換する。
def normalize(x):
B, C, H, W = x.shape
x = x.view(B, -1)
xmin = x.min(dim=1, keepdim=True)[0]
xmax = x.max(dim=1, keepdim=True)[0]
x = (x - xmin) / (xmax - xmin)
x = x.view(B, C, H, W)
return x
def tensor_to_images(x):
x = normalize(x)
x = x.cpu().numpy().transpose(0, 2, 3, 1)
x = (x * 255).astype(np.uint8)
if x.shape[3] == 1:
# (B, H, W, 1) -> (B, H, W)
x = x.squeeze(axis=3)
return x顕著正マップをグレースケール画像にする。
x.abs().sum(dim=1, keepdims=True) で各チャンネルの値を足し合わせて、(B, C, H, W) を (B, 1, H, W) にします。
def tensor_to_gray_images(x):
x = x.abs().sum(dim=1, keepdims=True)
x = tensor_to_images(x)
return x顕著正マップで値が正のピクセルだけ強調する。
torch.nn.functional.relu(x) で負の値は0としたテンソルを作成します。
def tensor_to_positive_saliency(x):
x = torch.nn.functional.relu(x)
x = tensor_to_images(x)
return x顕著正マップで値が負のピクセルだけ強調する。
torch.nn.functional.relu(-x) で正の値は0としたテンソルを作成します。
def tensor_to_negative_saliency(x):
x = torch.nn.functional.relu(-x)
x = tensor_to_images(x)
return xメインの処理
# Vanilla Backpropagation
vanilla_backprop = VanillaBackprop(model)
results = defaultdict(list)
for batch in dataloader:
# 順伝搬を行う。
class_ids = vanilla_backprop.forward(batch["image"])
for i in range(3): # top 1 ~ top 3
# i 番目にスコアが高いクラスを取得する。
ith_class_ids = class_ids[:, i]
# 逆伝搬を行う。
vanilla_backprop.backward(ith_class_ids)
# 入力画像に対する勾配を取得する。
gradients = vanilla_backprop.generate()
# 勾配を画像にする。
color_grad_imgs = tensor_to_images(gradients)
gray_grad_imgs = tensor_to_gray_images(gradients)
pos_grad_imgs = tensor_to_positive_saliency(gradients)
neg_grad_imgs = tensor_to_negative_saliency(gradients)
for j in range(len(batch["image"])):
img = batch["raw_image"][j].numpy()
img_path = batch["path"][j]
class_id = ith_class_ids[j]
color_grad = color_grad_imgs[j]
gray_grad = gray_grad_imgs[j]
pos_grad = pos_grad_imgs[j]
neg_grad = neg_grad_imgs[j]
result = {
"image": img,
"color_grad": color_grad,
"gray_grad": gray_grad,
"pos_grad": pos_grad,
"neg_grad": neg_grad,
"class_id": class_id,
"class_name": class_names[class_id],
}
results[img_path].append(result)for batch in dataloaderでループさせて、ミニバッチbatchを取得する。vanilla_backprop.forward(batch["image"])を呼び、確率が大きい順にソートされたクラス ID の一覧を取得する。- 確率が高い上位3クラスについて、見ていく。
ith_class_ids = class_ids[:, i]でi番目にスコアが高いクラス ID の一覧を取得します。vanilla_backprop.backward(ith_class_ids)で逆伝搬を行う。vanilla_backprop.generate()で入力画像の勾配を取得する。- 4通りの方法で、する。
- 結果は dict に記録する。
可視化する
作成した顕著性マップを matplotlib で可視化します。
def output_results(output_dir, results, name):
output_dir.mkdir(exist_ok=True)
for img_path, result in results.items():
fig = plt.figure(figsize=(10, 10))
ax = fig.add_subplot(4, 4, 1)
ax.set_axis_off()
ax.imshow(result[0]["image"])
# top1 ~ top3 スコアのクラスの勾配を描画する。
for i in range(3):
color_img = result[i]["color_grad"]
gray_img = result[i]["gray_grad"]
pos_grad = result[i]["pos_grad"]
neg_grad = result[i]["neg_grad"]
class_name = result[i]["class_name"]
ax = fig.add_subplot(4, 4, i * 4 + 5)
ax.imshow(color_img)
ax.set_ylabel(f"Top {i + 1} - {class_name}")
ax.set_xticks([])
ax.set_yticks([])
ax = fig.add_subplot(4, 4, i * 4 + 6)
ax.imshow(gray_img, cmap="jet")
ax.set_axis_off()
ax = fig.add_subplot(4, 4, i * 4 + 7)
ax.imshow(pos_grad, cmap="jet")
ax.set_axis_off()
ax = fig.add_subplot(4, 4, i * 4 + 8)
ax.imshow(neg_grad, cmap="jet")
ax.set_axis_off()
axes = fig.get_axes()
axes[1].set_title("Color Gradient")
axes[2].set_title("Grayscale Gradient")
axes[3].set_title("Positive Gradient")
axes[4].set_title("Negative Gradient")
# ax.set_title(f"top {i + 1} {class_name}", fontsize=10)
save_path = output_dir / f"{name}_{Path(img_path).stem}.png"
fig.savefig(save_path, bbox_inches="tight")
# 結果を保存する。
output_results(Path("output"), results, "vanilla_backprop")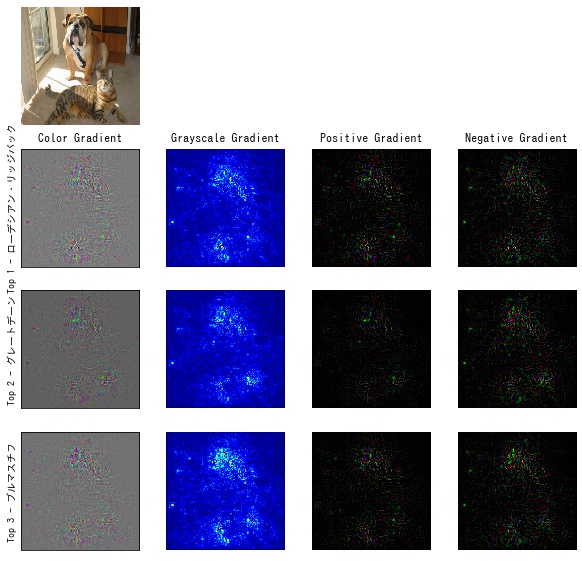
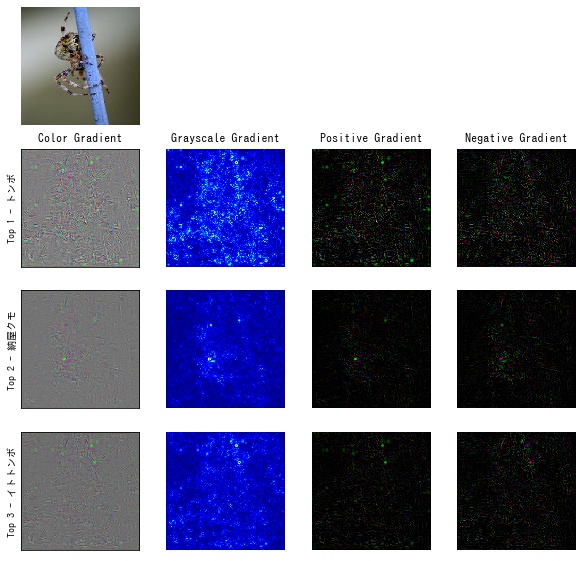
コメント