
概要
ディープラーニングの画像認識モデルである ResNeXt を解説し、Pytorch の実装例を紹介します。
ResNet
ResNet は、画像認識のコンテスト ILSVRC 2015 にて、top5 error rate で3.57%を記録し、優勝した CNN ネットワークモデルです。その後、いくつか改良したモデルが出てきて、今回紹介する WideResNet もその亜種になります。
[blogcard url=”https://pystyle.info/pytorch-resnet”]
Wide ResNet
論文の概要
ResNet では、層の数やチャンネル数が少ない薄い Residual Block を大量に重ねることで層が深いモデルを構築していましたが、この論文では、Residual Block の構造について様々なパターンで実験を行いました。その結果としてチャンネル数が多い Residual Block に変更することで、学習が高速になり、同程度のパラメータで精度もよくなることがわかりました。
diminishing feature reuse
ResNet では、学習中に勾配が Residual Block の重みのある方を通ることを強制できないので、いくつかの層でのみ有効な特徴表現を学習し、その他の層ではほとんど学習が行われず、これらの層は学習に貢献しないということが起こりえます。これを diminishing feature reuse といいます。
BatchNorm、ReLU の位置
Residual Block の Conv->BN->ReLU の順番を BN->ReLU->Conv に変更したほうが学習が早くなり、精度もよくなることがわかりました。

Residual Block の表現力を上げる
Residual Block の表現力を上げる方法として、次の3つの方法があります。
- 畳み込みのフィルタサイズを増やす
- 畳み込みの数を増やす
- 畳み込みの出力チャンネル数を増やす
畳み込みのフィルタサイズは 3×3 がよいことが実験的にわかっているため、フィルタサイズを 3×3 より大きくすることは検討せず、2、3について実験を行いました。Residual Block の畳み込みの数を $l$、チャンネル数をオリジナルの ResNet の何倍にするかを $k$、ResNet の畳み込みの合計数を $d$ で表すことにします。この表記法だと、オリジナルの Building Block は $l=2, k=1$ となります。
Residual Block の畳み込みの種類の検証
Residual Block の構造を $B(M)$ とします。$M$ は畳み込みのカーネルサイズの一覧です。例えば、$B(3, 1)$ とした場合、3×3 の畳み込みのあとに 1×1 の畳み込みを行う Residual Block を表します。
- B(1, 3, 1): 1×1 -> 3×3 -> 1×1。オリジナルの Bottleneck Block
- B(3, 1): 3×3 -> 1×1
- B(1, 3): 1×1 -> 3×3
- B(3, 1, 1): 3×3 -> 1×1 -> 1×1。Network In Network と同じ構造。
- B(3, 3): 3×3 -> 3×3。オリジナルの Building Block
- B(3, 1, 3): 3×3 -> 1×1 -> 3×3
Residual Block 内の畳み込みの構造 $B(M)$ を変化させ、$k=2$ で、パラメータ数がおよそ同じになるように畳み込みの合計数 $d$ を調整して、CIFAR-10 で実験を行った結果次のようになりました。
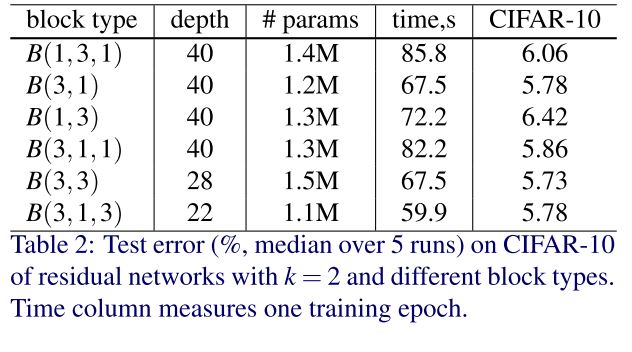
この結果から、畳み込みの種類は結果に大きくは影響しないとわかりました。 以降の実験では、畳み込みは 3×3 を使用することにします。
Residual Block の畳み込みの数
Residual Block 内の畳み込みの数 $l$ を変化させ、$k=2$ で、畳み込みの合計数は $d=40$ になるようにして、CIFAR-10 で実験を行った結果次のようになりました。

$l = 2$ が一番結果がよいことがわかったので、以降は $l = 2 (=B(3, 3))$ を使用することにします。
Residual Block の畳み込みの出力チャンネル数
Residual Block 内の畳み込みの数の出力チャンネル数を何倍にするかを表す $k$ を変化させ、CIFAR-10 で実験を行った結果次のようになりました。
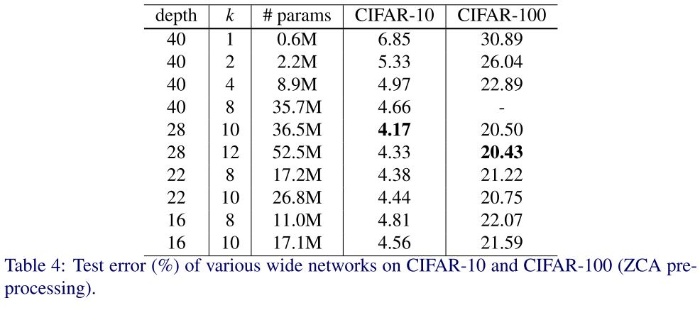
- $l = 16, 22, 40$ すべてで $k$ を増やすほど精度が上がることがわかりました。
- $k= 8, 10$ で固定した場合は層を増やすほど精度が上がりますが、層の数が40を超えると逆に精度が悪くなることがわかりました。チャンネル数を増やした場合、パラメータ数が増えるので、その分通常の ResNet よりは層を浅くしたほうがよいことがわかります。
他のモデルとの比較
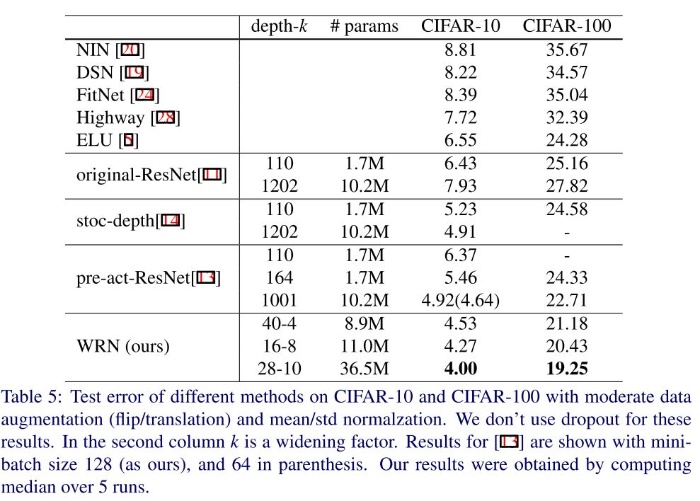
通常の ResNet-1001 より層の数が1/36である WRN-28-10 のほうが CIFAR-10 及び CIFAR-100 の精度が大幅に高いことがわかります。
Residual Block の正則化
畳み込みの数の出力チャンネル数が増え過学習のリスクが高まるので、正則化として Dropout を導入することを検討しました。
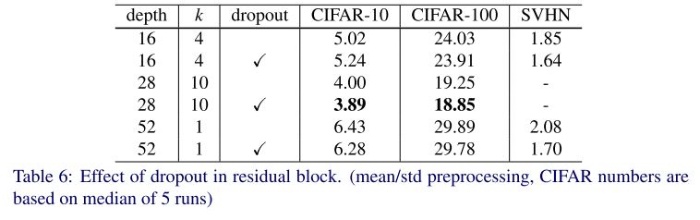
その結果、WRN-28-10, WRN-52-1 (K=1 なので通常の ResNet) ともに Dropout を導入したほうが性能が上がることがわかりました。
torchvision の Wide ResNet の実装
torchvision.models に、ResNet-50、ResNet-100 のチャンネル数をそれぞれ2倍にした wide_resnet50_2(), wide_resnet101_2() があります。ここでは、論文作者の Torch (lua) で実装された Cifer10 用の Wide Resnet wide-residual-networks/wide-resnet.lua を Pytroch で再現したものを紹介します。torchvision の実装はオリジナル実装とは異なりますが、実用上は torchvision のものを使いましょう。
ResNet の実装を一部変更したものなので、ResNet の実装については下記記事で解説し、その変更点のみこの記事で解説します。
[blogcard url=”https://pystyle.info/pytorch-resnet”]
Bottleneck Block の実装
BuildingBlock クラスで Building Block を定義しています。
wide-residual-networks/wide-resnet.lua の wide_basic() を Pytroch で再現すると以下の順番になります。
- BatchNorm2d
- ReLU
- Conv2D
- BatchNorm2d
- ReLU
- Dropout
- Conv2D
import torch
import torch.nn as nn
def conv3x3(in_channels, out_channels, stride=1):
return nn.Conv2d(
in_channels,
out_channels,
kernel_size=3,
stride=stride,
padding=1,
bias=False,
)
def conv1x1(in_channels, out_channels, stride=1):
return nn.Conv2d(
in_channels, out_channels, kernel_size=1, stride=stride, bias=False
)
class BuildingBlock(nn.Module):
def __init__(
self,
in_channels,
out_channels,
stride=1,
):
super().__init__()
self.bn1 = nn.BatchNorm2d(in_channels)
self.conv1 = conv3x3(in_channels, out_channels, stride)
self.bn2 = nn.BatchNorm2d(out_channels)
self.conv2 = conv3x3(out_channels, out_channels)
self.dropout = nn.Dropout(p=0.3)
self.relu = nn.ReLU(inplace=True)
# 入力と出力のチャンネル数が異なる場合、x をダウンサンプリングする。
if in_channels != out_channels:
self.shortcut = conv1x1(in_channels, out_channels, stride)
else:
self.shortcut = nn.Sequential()
def forward(self, x):
out = self.bn1(x)
out = self.relu(out)
out = self.conv1(out)
out = self.bn2(out)
out = self.relu(out)
out = self.dropout(out)
out = self.conv2(out)
out += self.shortcut(x)
return outWide ResNet を定義する
WideResNet クラスで Wide ResNet 全体のモデルを作成します。層の深さ depth とチャンネル数を何倍するかを表す k を引数にとります。Cifar10 用なので、入力サイズは (32, 32) を想定しています。
class WideResNet(nn.Module):
def __init__(self, depth, k, num_classes=10):
super().__init__()
assert (depth - 4) % 6 == 0, "depth should be 6n + 4"
n = (depth - 4) // 6
channles = [16, 16 * k, 32 * k, 64 * k]
self.conv1 = conv3x3(3, channles[0])
self.layer1 = self._make_layer(channles[0], channles[1], n)
self.layer2 = self._make_layer(channles[1], channles[2], n, stride=2)
self.layer3 = self._make_layer(channles[2], channles[3], n, stride=2)
self.bn = nn.BatchNorm2d(channles[3])
self.relu = nn.ReLU(inplace=True)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(channles[3], num_classes)
# 重みを初期化する。
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode="fan_in", nonlinearity="relu")
elif isinstance(m, nn.Linear):
nn.init.constant_(m.bias, 0)
def _make_layer(self, in_channels, out_channels, blocks, stride=1):
layers = []
# 最初の Residual Block
layers.append(BuildingBlock(in_channels, out_channels, stride))
# 残りの Residual Block
for _ in range(1, blocks):
layers.append(BuildingBlock(out_channels, out_channels))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.bn(x)
x = self.relu(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x畳み込み層のカーネルは $N(0, \sqrt{\frac{2}{\text{fan\_in}}})$ で初期化されているので、Pytroch では nn.init.kaiming_normal_(m.weight, mode="fan_in", nonlinearity="relu") になります。
function utils.MSRinit(model)
for k,v in pairs(model:findModules('nn.SpatialConvolution')) do
local n = v.kW*v.kH*v.nInputPlane
v.weight:normal(0,math.sqrt(2/n))
if v.bias then v.bias:zero() end
end
end全結合層のバイアスは0で初期化します。
function utils.FCinit(model)
for k,v in pairs(model:findModules'nn.Linear') do
v.bias:zero()
end
end畳み込み層の数が depth となるように3つの Building Blocks の繰り返し数を n = (depth - 4) // 6 で決めます。4は Shortcut Connection の畳み込み層3つと入力層の次の畳み込み層の数です。
論文に記載されているパラメータ数と一致することを確認します。
def num_params(model):
return sum(x.numel() for x in model.parameters() if x.requires_grad)
params = [
(40, 1),
(40, 2),
(40, 4),
(40, 8),
(28, 10),
(28, 12),
(22, 8),
(22, 10),
(16, 8),
(16, 10),
]
for d, k in params:
model = WideResNet(d, k, num_classes=10)
n_params = num_params(model)
print(f"d={d}, k={k}, n_params={n_params / 1e6:.1f}M")d=40, k=1, n_params=0.6M d=40, k=2, n_params=2.2M d=40, k=4, n_params=8.9M d=40, k=8, n_params=35.7M d=28, k=10, n_params=36.5M d=28, k=12, n_params=52.5M d=22, k=8, n_params=17.2M d=22, k=10, n_params=26.8M d=16, k=8, n_params=11.0M d=16, k=10, n_params=17.1M
ResNet、ResNext、Wide ResNet のモデル一覧
以下の表のモデルは記事で紹介した実装ではなく、torchvision 版の Wide ResNet です。
| モデル名 | 関数 | パラメータ数 | Top-1 エラー率 | Top-5 エラー率 |
|---|---|---|---|---|
| ResNet-18 | resnet18() | 11689512 | 30.24 | 10.92 |
| ResNet-34 | resnet34() | 21797672 | 26.7 | 8.58 |
| ResNet-50 | resnet50() | 25557032 | 23.85 | 7.13 |
| ResNet-101 | resnet101() | 44549160 | 22.63 | 6.44 |
| ResNet-152 | resnet152() | 60192808 | 21.69 | 5.94 |
| ResNeXt-50-32x4d | resnext50_32x4d() | 25028904 | 22.38 | 6.3 |
| ResNeXt-101-32x8d | resnext101_32x8d() | 88791336 | 20.69 | 5.47 |
| Wide ResNet-50-2 | wide_resnet50_2() | 68883240 | 21.49 | 5.91 |
| Wide ResNet-101-2 | wide_resnet101_2() | 126886696 | 21.16 | 5.72 |
コメント