
概要
ディープラーニングの画像認識モデルである Inception v3 を解説し、Pytorch の実装例を紹介します。
Inception v3
GoogLeNet (Inception v1) を改良したモデルである Inception v3 について、論文 Rethinking the Inception Architecture for Computer Vision に基づいて解説します。Inception v3 は GoogLeNet (Inception v1) の Inception Module を次に紹介するテクニックで変更したものです。
1. 小さい畳み込み層に置き換える
7×7 や 5×5 のようにカーネルサイズが大きい畳み込みは計算コストが高いです。1×1 の畳み込みの計算量を1とした場合、nxn の畳み込みの計算量は $n^2$ 倍になります。しかし、カーネルサイズを単に小さくしただけでは受容野 (receptive field) が狭くなり、表現力が低下します。その代わりに 3×3 の畳み込み層を複数使用することで、受容野を同じにしつつ、計算量の削減を図ります。例えば、5×5 の畳み込み層は 3×3 の畳み込み層2つで置き換えます。この場合、計算量は $(9 * 2) / 25 = 0.72$ 倍に削減できます。
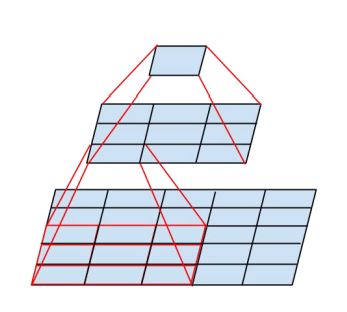
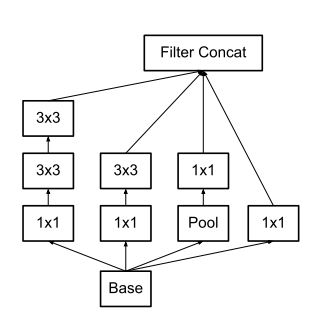
2. 非対称な畳み込み層に置き換える
nxn の畳み込み層は、nx1 の畳み込み層と 1xn の畳み込み層を使用することで、受容野を同じにしつつ、計算量の削減を図ります。例えば、7×7 の畳み込み層を 7×1 と 1×7 の畳み込み層に置き換えた場合、計算量は $2 \cdot 7 / 49 = 0.28$ 倍に削減できます。
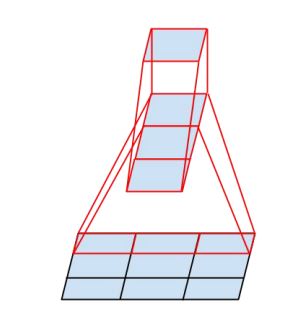
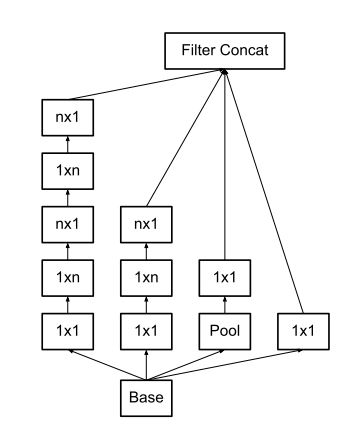
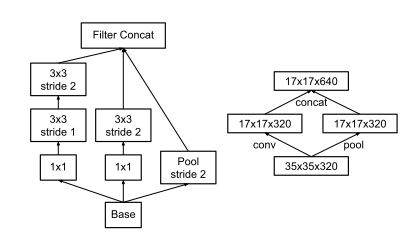
3. プーリングと畳み込みを並列して行い、大きさを小さくする
プーリングにより特徴マップの大きさを小さくすることで計算量を削減できますが、同時に表現力も低下してしまいます。そのため、プーリングの他に 3×3、stride=2 の畳み込みを並行して実行することで、表現力を維持しつつ、特徴マップの大きさを削減しています。
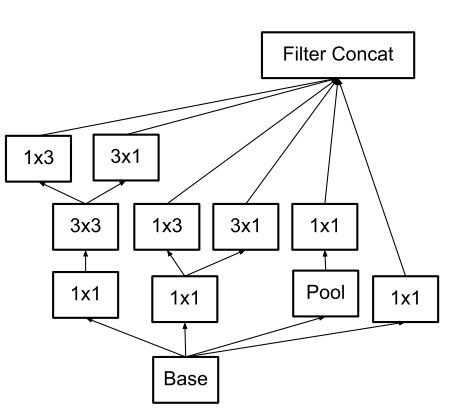
4. 分岐を利用して出力チャンネル数を増やす
表現力を増やすために、出力チャンネル数を倍にすることを考えたとき、nxn の畳み込み層1つで行う代わりに出力チャンネル数が半分の 1xn と nx1 のチャンネルで並列して行い、チャンネル方向に結合することで計算量を削減できます。出力チャンネル数を 2C にする 3×3 の畳み込み層を出力チャンネル数が C の 3×1 と 1×3 の畳み込み層に置き換えた場合、計算量は $(6 * C) / (9 * 2C) = 0.66$ 倍に削減できます。

Auxiliary Classifier
GoogleNet (Inception v1) では、学習を早くする目的で補助の分類器 (Auxiliary Classifier) を2つ用意し、3つの出力を重み付き平均をとり、損失を計算します。補助の分類器 (Auxiliary Classifier) を2つ用意し、3つの出力を重み付き平均をとり、損失を計算していました。しかし、その後の調査で Auxiliary Classifier は学習を早くする効果はなく、学習終盤でモデルを正則化をする効果があることがわかりました。また、2つあった Auxiliary Classifier のうち、層が浅い方を削除しても影響がないことがわかりました。そのため、Inception v3 では、Auxiliary Classifier は1つだけ残しています。
torchvision の実装
torchvision.models.inception_v3() で利用できます。
| モデル名 | 関数名 | パラメータ数 | Top-1 エラー率 | Top-5 エラー率 |
|---|---|---|---|---|
| Inception v3 | inception_v3() | 27161264 | 22.55 | 6.44 |
import torchvision
model = torchvision.models.inception_v3()Pytorch の実装
紹介するコードは、以下の2つの実装を参考に解説用に構成したものです。実用上は torchvision.models.inception_v3() を使用してください。
- tensorflow/models の実装 (オリジナル実装)
- torchvision の実装
torchvision の実装は tensorflow/models のオリジナル実装が元になっており、論文といくつかの点で異なります。
- 畳み込み層の直後に BatchNorm2d を入れています。
- 全結合層の直前のプーリング層は、入力サイズが (N, 3, 299, 299) と異なる場合でも対応できるように AdaptiveAvgPool2d に変更しています。
畳み込み層の定義
畳み込み層はすべて Conv2d -> BatchNorm2d -> ReLU という順番で処理を行うので、モジュール化します。
import torch
import torch.nn as nn
import torch.nn.functional as F
class BasicConv2d(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs):
super().__init__()
self.conv = nn.Conv2d(in_channels, out_channels, bias=False, **kwargs)
self.bn = nn.BatchNorm2d(out_channels, eps=0.001)
self.relu = nn.ReLU(True)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.relu(x)
return xAuxiliary Classifier の定義
Auxiliary Classifier を作成します。
- models/inception_v3.py L512 に従い、2つ目の畳み込み層の重みは $mean=0, std=0.01$ の切断正規分布で初期化します。
- models/inception_v3.py L516 に従い、全結合層の重みは $mean=0, std=0.001$ の切断正規分布で初期化します。
class InceptionAux(nn.Module):
def __init__(self, in_channels, num_classes):
super().__init__()
self.pool1 = nn.AvgPool2d(kernel_size=5, stride=3)
self.conv0 = BasicConv2d(in_channels, 128, kernel_size=1)
self.conv1 = BasicConv2d(128, 768, kernel_size=5)
self.conv1.stddev = 0.01
self.pool2 = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(768, num_classes)
self.fc.stddev = 0.001
def forward(self, x):
x = self.pool1(x) # (N, 768, 17, 17)
x = self.conv0(x) # (N, 768, 5, 5)
x = self.conv1(x) # (N, 128, 5, 5)
x = self.pool2(x) # (N, 768, 1, 1)
x = torch.flatten(x, 1) # (N, 768)
x = self.fc(x) # (N, 1000)
return xInception Module A
Inception Module A を作成します。GoogLeNet の Inception Module の 5×5 の畳み込み層を、小さい畳み込み層に置き換えるテクニックを使用して、2つの 3×3 の畳み込み層に置き換えたものになります。

class InceptionA(nn.Module):
def __init__(self, in_channels, pool_features):
super().__init__()
self.branch1x1 = BasicConv2d(in_channels, 64, kernel_size=1)
self.branch5x5 = nn.Sequential(
BasicConv2d(in_channels, 48, kernel_size=1),
BasicConv2d(48, 64, kernel_size=5, padding=2),
)
self.branch3x3db1 = nn.Sequential(
BasicConv2d(in_channels, 64, kernel_size=1),
BasicConv2d(64, 96, kernel_size=3, padding=1),
BasicConv2d(96, 96, kernel_size=3, padding=1),
)
self.branch_pool = nn.Sequential(
nn.AvgPool2d(kernel_size=3, stride=1, padding=1),
BasicConv2d(in_channels, pool_features, kernel_size=1),
)
def forward(self, x):
branch1x1 = self.branch1x1(x)
branch5x5 = self.branch5x5(x)
branch3x3db1 = self.branch3x3db1(x)
branch_pool = self.branch_pool(x)
out = torch.cat([branch1x1, branch5x5, branch3x3db1, branch_pool], 1)
return outInception Module B
Inception Module B を作成します。プーリングと畳み込みを並列して行い、大きさを小さくするテクニックを使用して、出力サイズを半分にしています。
class InceptionB(nn.Module):
def __init__(self, in_channels):
super().__init__()
self.branch3x3 = BasicConv2d(in_channels, 384, kernel_size=3, stride=2)
self.branch3x3db1 = nn.Sequential(
BasicConv2d(in_channels, 64, kernel_size=1),
BasicConv2d(64, 96, kernel_size=3, padding=1),
BasicConv2d(96, 96, kernel_size=3, stride=2),
)
self.branch_pool = nn.MaxPool2d(kernel_size=3, stride=2)
def forward(self, x):
branch3x3 = self.branch3x3(x)
branch3x3db1 = self.branch3x3db1(x)
branch_pool = self.branch_pool(x)
out = torch.cat([branch3x3, branch3x3db1, branch_pool], 1)
return outInception Module C
Inception Module C を作成します。7×7 の畳み込み層を非対称な畳み込み層に置き換えるテクニックを使用しています。
class InceptionC(nn.Module):
def __init__(self, in_channels, ch7x7):
super().__init__()
# fmt: off
self.branch1x1 = BasicConv2d(in_channels, 192, kernel_size=1)
self.branch7x7 = nn.Sequential(
BasicConv2d(in_channels, ch7x7, kernel_size=1),
BasicConv2d(ch7x7, ch7x7, kernel_size=(1, 7), padding=(0, 3)),
BasicConv2d(ch7x7, 192, kernel_size=(7, 1), padding=(3, 0)),
)
self.branch7x7dbl = nn.Sequential(
BasicConv2d(in_channels, ch7x7, kernel_size=1),
BasicConv2d(ch7x7, ch7x7, kernel_size=(7, 1), padding=(3, 0)),
BasicConv2d(ch7x7, ch7x7, kernel_size=(1, 7), padding=(0, 3)),
BasicConv2d(ch7x7, ch7x7, kernel_size=(7, 1), padding=(3, 0)),
BasicConv2d(ch7x7, 192, kernel_size=(1, 7), padding=(0, 3))
)
self.branch_pool = nn.Sequential(
nn.AvgPool2d(kernel_size=3, stride=1, padding=1),
BasicConv2d(in_channels, 192, kernel_size=1),
)
# fmt: on
def forward(self, x):
branch1x1 = self.branch1x1(x)
branch7x7 = self.branch7x7(x)
branch7x7dbl = self.branch7x7dbl(x)
branch_pool = self.branch_pool(x)
out = torch.cat([branch1x1, branch7x7, branch7x7dbl, branch_pool], 1)
return outInception Module D
Inception Module D を作成します。7×7 の畳み込み層を非対称な畳み込み層に置き換えるテクニックを使用しています。また、プーリングと畳み込みを並列して行い、大きさを小さくするテクニックを使用して、出力サイズを半分にしています。
class InceptionD(nn.Module):
def __init__(self, in_channels):
super().__init__()
self.branch3x3 = nn.Sequential(
BasicConv2d(in_channels, 192, kernel_size=1),
BasicConv2d(192, 320, kernel_size=3, stride=2),
)
self.branch7x7x3 = nn.Sequential(
BasicConv2d(in_channels, 192, kernel_size=1),
BasicConv2d(192, 192, kernel_size=(1, 7), padding=(0, 3)),
BasicConv2d(192, 192, kernel_size=(7, 1), padding=(3, 0)),
BasicConv2d(192, 192, kernel_size=3, stride=2),
)
self.branch_pool = nn.MaxPool2d(kernel_size=3, stride=2)
def forward(self, x):
branch3x3 = self.branch3x3(x)
branch7x7x3 = self.branch7x7x3(x)
branch_pool = self.branch_pool(x)
out = torch.cat([branch3x3, branch7x7x3, branch_pool], 1)
return outInception Module E
Inception Module E を作成します。出力チャンネル数を増やす役割がある Inception Module のため、2つの分岐で出力数を倍に増やしています。その際に 3×3 の1つの畳み込み層で行う代わりに 1×3 と 3×1 の畳み込み層で並行して行い、チャンネル方向に結合することで計算量を削減しています。
class InceptionE(nn.Module):
def __init__(self, in_channels):
super().__init__()
self.branch1x1 = BasicConv2d(in_channels, 320, kernel_size=1)
self.branch3x3_1 = BasicConv2d(in_channels, 384, kernel_size=1)
self.branch3x3_2a = BasicConv2d(384, 384, kernel_size=(1, 3), padding=(0, 1))
self.branch3x3_2b = BasicConv2d(384, 384, kernel_size=(3, 1), padding=(1, 0))
self.branch3x3dbl_1 = BasicConv2d(in_channels, 448, kernel_size=1)
self.branch3x3dbl_2 = BasicConv2d(448, 384, kernel_size=3, padding=1)
self.branch3x3dbl_3a = BasicConv2d(384, 384, kernel_size=(1, 3), padding=(0, 1))
self.branch3x3dbl_3b = BasicConv2d(384, 384, kernel_size=(3, 1), padding=(1, 0))
self.branch_pool = nn.Sequential(
nn.AvgPool2d(kernel_size=3, stride=1, padding=1),
BasicConv2d(in_channels, 192, kernel_size=1),
)
def forward(self, x):
branch1x1 = self.branch1x1(x)
branch3x3 = self.branch3x3_1(x)
branch3x3 = [
self.branch3x3_2a(branch3x3),
self.branch3x3_2b(branch3x3),
]
branch3x3 = torch.cat(branch3x3, 1)
branch3x3dbl = self.branch3x3dbl_1(x)
branch3x3dbl = self.branch3x3dbl_2(branch3x3dbl)
branch3x3dbl = [
self.branch3x3dbl_3a(branch3x3dbl),
self.branch3x3dbl_3b(branch3x3dbl),
]
branch3x3dbl = torch.cat(branch3x3dbl, 1)
branch_pool = self.branch_pool(x)
out = torch.cat([branch1x1, branch3x3, branch3x3dbl, branch_pool], 1)
return outInceptionv3 本体を定義する
Inception v3 本体を定義します。各パラメータは以下のようになっています。
| 名称 | 出力の形状 | out_features | kernel_size | stride | padding |
|---|---|---|---|---|---|
| Input | (N, 3, 299, 299) | ||||
| Conv2d_1a_3x3 | (N, 32, 149, 149) | 32 | 3 | 2 | 0 |
| Conv2d_2a_3x3 | (N, 32, 147, 147) | 32 | 3 | 1 | 0 |
| Conv2d_2b_3x3 | (N, 64, 147, 147) | 64 | 3 | 1 | 1 |
| MaxPool_3a_3x3 | (N, 64, 73, 73) | 3 | 2 | 0 | |
| Conv2d_3b_1x1 | (N, 80, 73, 73) | 80 | 1 | 1 | 0 |
| Conv2d_4a_3x3 | (N, 192, 71, 71) | 192 | 3 | 1 | 0 |
| MaxPool_5a_3x3 | (N, 192, 35, 35) | 3 | 2 | 0 | |
| Mixed_5b (A) | (N, 256, 35, 35) | ||||
| Mixed_5c (A) | (N, 288, 35, 35) | ||||
| Mixed_5d (A) | (N, 288, 35, 35) | ||||
| Mixed_6a (B) | (N, 768, 17, 17) | ||||
| Mixed_6b (C) | (N, 768, 17, 17) | ||||
| Mixed_6c (C) | (N, 768, 17, 17) | ||||
| Mixed_6d (C) | (N, 768, 17, 17) | ||||
| Mixed_6e (C) | (N, 768, 17, 17) | ||||
| Mixed_7a (D) | (N, 1280, 8, 8) | ||||
| Mixed_7b (E) | (N, 2048, 8, 8) | ||||
| Mixed_7c (E) | (N, 2048, 8, 8) | ||||
| GlobalAvgPool | (N, 2048, 1, 1) | ||||
| Dropout | (N, 2048, 1, 1) | ||||
| Flatten | (N, 2048) | ||||
| Linear | (N, 1000) |
- ドロップアウトの割合は models/inception_v3.py に従い、0.2 としました。
- 論文に初期化方法は記載がないため、tensorflow/models の実装 のやり方で初期化しました。
- 全結合層、畳み込み層の重みは Xavier (tf-slim の実装 tf-slim/initializers.py に従い、$[-\sqrt{\frac{3}{n}}, \sqrt{\frac{3}{n}}], n = (fan\_in + fan\_out) / 2$ の一様分布)、バイアスは0で初期化します。しかし、Pytorch の
kaiming_uniform_()には $(fan\_in + fan\_out) / 2$ とするモードがないため、デフォルトの mode=”fan_in” を使用します。 - ただし、Auxiliary Classifier の2つの層の重みだけ、切断正規分布で初期化します。
- 全結合層、畳み込み層の重みは Xavier (tf-slim の実装 tf-slim/initializers.py に従い、$[-\sqrt{\frac{3}{n}}, \sqrt{\frac{3}{n}}], n = (fan\_in + fan\_out) / 2$ の一様分布)、バイアスは0で初期化します。しかし、Pytorch の
class Inception3(nn.Module):
def __init__(
self,
num_classes=1000,
aux_logits=True,
dropout=0.2,
):
super().__init__()
self.aux_logits = aux_logits
self.conv_1a_3x3 = BasicConv2d(3, 32, kernel_size=3, stride=2)
self.conv_2a_3x3 = BasicConv2d(32, 32, kernel_size=3)
self.conv_2b_3x3 = BasicConv2d(32, 64, kernel_size=3, padding=1)
self.maxpool_3a_3x3 = nn.MaxPool2d(kernel_size=3, stride=2)
self.conv_3b_1x1 = BasicConv2d(64, 80, kernel_size=1)
self.conv_4a_3x3 = BasicConv2d(80, 192, kernel_size=3)
self.maxpool_3a_3x3 = nn.MaxPool2d(kernel_size=3, stride=2)
self.miaxed_5b = InceptionA(192, pool_features=32)
self.miaxed_5c = InceptionA(256, pool_features=64)
self.miaxed_5d = InceptionA(288, pool_features=64)
self.miaxed_6a = InceptionB(288)
self.miaxed_6b = InceptionC(768, ch7x7=128)
self.miaxed_6c = InceptionC(768, ch7x7=160)
self.miaxed_6d = InceptionC(768, ch7x7=160)
self.miaxed_6e = InceptionC(768, ch7x7=192)
self.aux = InceptionAux(768, num_classes) if aux_logits else None
self.miaxed_7a = InceptionD(768)
self.miaxed_7b = InceptionE(1280)
self.miaxed_7c = InceptionE(2048)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.dropout = nn.Dropout(p=dropout)
self.fc = nn.Linear(2048, num_classes)
self._initialize_weights()
def _initialize_weights(self):
for m in self.modules():
if hasattr(m, "stddev"):
# Auxiliary Classifier の2つの層
nn.init.trunc_normal_(m.weight, std=stddev)
nn.init.zeros_(m.bias)
elif isinstance(m, nn.Conv2d):
nn.init.kaiming_uniform_(m.weight, nonlinearity="conv2d")
nn.init.zeros_(m.bias)
elif isinstance(m, nn.Linear):
nn.init.kaiming_uniform_(m.weight, nonlinearity="linear")
nn.init.zeros_(m.bias)
def forward(self, x):
x = self.conv_1a_3x3(x) # (N, 32, 149, 149)
x = self.conv_2a_3x3(x) # (N, 32, 147, 147)
x = self.conv_2b_3x3(x) # (N, 64, 147, 147)
x = self.maxpool_3a_3x3(x) # (N, 64, 73, 73)
x = self.conv_3b_1x1(x) # (N, 80, 73, 73)
x = self.conv_4a_3x3(x) # (N, 192, 71, 71)
x = self.maxpool_3a_3x3(x) # (N, 192, 35, 35)
x = self.miaxed_5b(x) # (N, 256, 35, 35)
x = self.miaxed_5c(x) # (N, 288, 35, 35)
x = self.miaxed_5d(x) # (N, 288, 35, 35)
x = self.miaxed_6a(x) # (N, 768, 17, 17)
x = self.miaxed_6b(x) # (N, 768, 17, 17)
x = self.miaxed_6c(x) # (N, 768, 17, 17)
x = self.miaxed_6d(x) # (N, 768, 17, 17)
x = self.miaxed_6e(x) # (N, 768, 17, 17)
aux = self.aux(x) if self.aux_logits and self.training else None
x = self.miaxed_7a(x) # (N, 1280, 8, 8)
x = self.miaxed_7b(x) # (N, 2048, 8, 8)
x = self.miaxed_7c(x) # (N, 2048, 8, 8)
x = self.avgpool(x)
x = self.dropout(x) # (N, 2048, 1, 1)
x = torch.flatten(x, 1) # (N, 2048)
x = self.fc(x) # (N, 1000)
if self.training and self.aux_logits:
return x, aux
else:
return aux
def inception_v3():
return Inception3()
コメント