
概要
物体検出の YOLOv3 モデルについて解説します。実装例は nekobean/pytorch_yolov3 を参照してください。
関連記事
[blogcard url=”https://pystyle.info/pytorch-yolov3-explain-yolo-layer”]
[blogcard url=”https://pystyle.info/pytorch-yolov3-how-to-train-custom-dataset”]
[blogcard url=”https://pystyle.info/pytorch-yolov3-how-to-use-pretrained-model”]
DarkNet 53
DarkNet 53 は、53層の畳み込み層で構成されるクラス分類用のモデルです。YOLOv3 では ImageNet で DarkNet 53 を学習し、出力層の 1×1 の畳み込みを除いた52層の畳み込み層を特徴抽出するための Backbone に使います。
| 層の種類 | 出力の形状 | out_channels | kernel_size | padding | stride | 畳み込み層の数 |
|---|---|---|---|---|---|---|
| 入力 | (N, 32, 608, 608) | |||||
| conv | (N, 32, 608, 608) | 32 | 3 | 1 | 1 | 1 |
| conv | (N, 64, 304, 304) | 64 | 3 | 1 | 2 | 1 |
| Residual Block x1 | (N, 64, 304, 304) | 2 | ||||
| conv | (N, 128, 152, 152) | 128 | 3 | 1 | 2 | 1 |
| Residual Block x 2 | (N, 128, 152, 152) | 4 | ||||
| conv | (N, 256, 76, 76) | 256 | 3 | 1 | 2 | 1 |
| Residual Block x 8 | (N, 256, 76, 76) | 16 | ||||
| conv | (N, 512, 38, 38) | 512 | 3 | 1 | 2 | 1 |
| Residual Block x 8 | (N, 512, 38, 38) | 16 | ||||
| conv | (N, 1024, 19, 19) | 1024 | 3 | 1 | 2 | 1 |
| Residual Block x 4 | (N, 1024, 19, 19) | 8 | ||||
| conv | (N, 1000, 19, 19) | 1000 | 1 | 0 | 1 | 1 |
| Global Average Pooling | (N, 1000, 1, 1) | |||||
| Flatten | (N, 1000) |
- 最後の 1×1 の畳み込みは特徴マップのチャンネル数を ImageNet のクラス数1000に変更するためのものです。
- Global Average Pooling を行うため、入力サイズは (608, 608) 以外でも可能です。
Residual Block は 1×1 の畳み込みでチャンネル数を半分にしたあと、3×3 の畳み込み層でチャンネル数を元に戻す Residual Block です

Residual Block プーリング層の代わりに stride=2 の 3×3 の畳み込みで特徴マップのサイズを削減します。
- すべての層のあとには、Batch Normalization と Leaky ReLU がついてます。

YOLOv3
モデルの構造

- DarkNet 53 のうち、出力層の 1×1 の畳み込みを除いた52層の畳み込み層を特徴抽出するための Backbone に使います。
- 様々なスケールの物体に対応するために、特徴マップの大きさに応じて、3つの出力層があります。
- 出力チャンネル数が
Cとなっているところは YOLO Layer が必要とするチャンネル数C = (クラス数 + 5) * Anchor Box の数を意味します。 - YOLO Layer は出力または損失を計算するレイヤーです。YOLOv3 – 損失計算や推論結果の生成を行う YOLO レイヤーについて解説 という記事を参照してください。
- 入力サイズは 608×608 でなくてもよいですが、YOLOv3 の構造上、32の倍数である必要があります。
| No | ブロック名 | 層の種類 | 出力の形状 | out_channels | kernel_size | padding | stride |
|---|---|---|---|---|---|---|---|
| 入力 | (N, 32, 608, 608) | ||||||
| 1 | Darknet 53 | conv | (N, 32, 608, 608) | 32 | 3 | 1 | 1 |
| 2 | Darknet 53 | conv | (N, 64, 304, 304) | 64 | 3 | 1 | 2 |
| 3 | Darknet 53 | Residual Block x1 | (N, 64, 304, 304) | ||||
| 4 | Darknet 53 | conv | (N, 128, 152, 152) | 128 | 3 | 1 | 2 |
| 5 | Darknet 53 | Residual Block x 2 | (N, 128, 152, 152) | ||||
| 6 | Darknet 53 | conv | (N, 256, 76, 76) | 256 | 3 | 1 | 2 |
| 7 | Darknet 53 | Residual Block x 8 | (N, 256, 76, 76) | ||||
| 8 | Darknet 53 | conv | (N, 512, 38, 38) | 512 | 3 | 1 | 2 |
| 9 | Darknet 53 | Residual Block x 8 | (N, 512, 38, 38) | ||||
| 10 | Darknet 53 | conv | (N, 1024, 19, 19) | 1024 | 3 | 1 | 2 |
| 11 | Darknet 53 | Residual Block x 4 | (N, 1024, 19, 19) | ||||
| 12 | A | conv | (N, 512, 19, 19) | 512 | 1 | 0 | 1 |
| 13 | A | conv | (N, 1024, 19, 19) | 1024 | 3 | 1 | 1 |
| 14 | A | conv | (N, 512, 19, 19) | 512 | 1 | 0 | 1 |
| 15 | A | conv | (N, 1024, 19, 19) | 1024 | 3 | 1 | 1 |
| 16 | A | conv | (N, 512, 19, 19) | 512 | 1 | 0 | 1 |
| 17 | B | conv | (N, 1024, 19, 19) | 1024 | 3 | 1 | 1 |
| 18 | B | conv | (N, C, 19, 19) | C | 1 | 0 | 1 |
| 19 | YOLO Layer | ||||||
| 20 | C | conv | (N, 256, 19, 19) | 256 | 1 | 0 | 1 |
| 21 | C | Upsampling | (N, 256, 38, 38) | ||||
| 22 | Concat (No21 + No9) | (N, 768, 38, 38) | |||||
| 23 | A | conv | (N, 256, 38, 38) | 256 | 1 | 0 | 1 |
| 24 | A | conv | (N, 512, 38, 38) | 512 | 3 | 1 | 1 |
| 25 | A | conv | (N, 256, 38, 38) | 256 | 1 | 0 | 1 |
| 26 | A | conv | (N, 512, 38, 38) | 512 | 3 | 1 | 1 |
| 27 | A | conv | (N, 256, 38, 38) | 256 | 1 | 0 | 1 |
| 28 | B | conv | (N, 512, 38, 38) | 512 | 3 | 1 | 1 |
| 29 | B | conv | (N, C, 38, 38) | C | 1 | 0 | 1 |
| 30 | YOLO Layer | ||||||
| 31 | C | conv | (N, 128, 38, 38) | 128 | 1 | 0 | 1 |
| 32 | C | Upsampling | (N, 128, 76, 76) | ||||
| 33 | Concat (No32 + No7) | (N, 384, 76, 76) | |||||
| 34 | A | conv | (N, 128, 76, 76) | 128 | 1 | 0 | 1 |
| 35 | A | conv | (N, 256, 76, 76) | 256 | 3 | 1 | 1 |
| 36 | A | conv | (N, 128, 76, 76) | 128 | 1 | 0 | 1 |
| 37 | A | conv | (N, 256, 76, 76) | 256 | 3 | 1 | 1 |
| 38 | A | conv | (N, 128, 76, 76) | 128 | 1 | 0 | 1 |
| 39 | B | conv | (N, 256, 76, 76) | 256 | 3 | 1 | 1 |
| 40 | B | conv | (N, C, 76, 76) | C | 1 | 0 | 1 |
| 41 | YOLO Layer |
出力や損失の計算
以下を参照してください
[blogcard url=”https://pystyle.info/pytorch-yolov3-explain-yolo-layer”]
前処理
モデルに入力する前に以下の処理を行います。
- Letter Box 処理: モデルの入力サイズと同じ固定の色で塗りつぶした画像を作成し、そこに入力画像をアスペクト比を固定して長辺が丁度一致するようにリサイズしたあと、貼り付けます。推論時は余白が均等になるように貼り付けます。
- 値の範囲を [0, 255] を [0, 1] に正規化します。

後処理
Score = Object Score * Class Scoreとし、この値が閾値未満の矩形は削除します。- クラスごとに独立して Non Maximum Suppression を行い、1つの物体に対して重複している矩形は削除します。
オーグメンテーション
Darknet の学習では以下のオーグメンテーションを行っています。
- jitter: アスペクト比をランダムに変更にします。
- random_placing: Letter Box 処理のときに画像を貼り付ける位置をランダムにします。
- ランダムに左右反転にします。
- ランダムに Hue、Saturation、Brightness を変更します。
- ランダムにモデルの入力サイズを変更します。(320, 352, 384, 416, 448, 480, 512, 544, 576, 608 のいずれか)
学習
学習率は、ベースとなる学習率 (base_lr) を以下のスケジューラーで調整します。
- 最初の
burnin_stepイテレーションは burn-in フェーズといって、小さい学習率から徐々に base_lr まで増やします。 - burnin_step 以上、
steps[0]未満のイテレーションは、学習率をbase_lrにします。 steps[0]以上、steps[1]未満のイテレーションは、学習率をbase_lr * 0.1にします。steps[1]以上のイテレーションは、学習率をbase_lr * 0.01にします。
import matplotlib.pyplot as plt
import numpy as np
def schedule(i, burnin_step, steps):
if i < burnin_step:
factor = (i / 1000) ** 4
elif i < steps[0]:
factor = 1.0
elif i < steps[1]:
factor = 0.1
else:
factor = 0.01
return factor
base_lr = 0.1
max_steps = 10000
steps = np.arange(max_steps)
lr = [base_lr * schedule(i, burnin_step=1000, steps=[8000, 9000]) for i in range(max_steps)]
fig, ax = plt.subplots()
ax.plot(steps, lr)
ax.set_xlabel("Steps")
ax.set_ylabel("Learning Rate")
plt.show()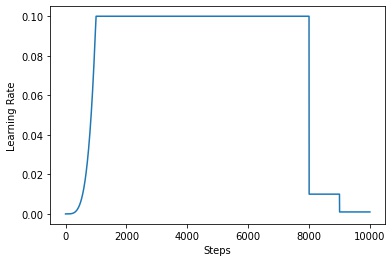
コメント