
概要
ディープラーニングの画像認識モデルである VGG を解説し、Pytorch の実装例を紹介します。
VGG
VGG は、画像認識のコンテスト ILSVRC 2015 にて、top5 error rate で3.57%を記録し、優勝した CNN ネットワークモデルです。下記、論文に基づいて解説します。
VGG の構造
VGG は複数の畳み込み層からなる特徴抽出を行う部分と抽出した特徴からクラス分類を行う部分に分かれています。特徴抽出部分では、次のルールで畳み込み層、プーリング層を並べています。
- 3×3 の畳み込み層のみ使用する
- プーリングにより特徴マップの形状を半分にした場合、次の畳み込み層で出力チャンネル数を倍にする
活性化関数はすべて ReLU を使用します。論文では、畳み込み層の数が異なる次の 6種類のモデルを検証しました。図の LRN とは、AlexNet で使われていた Local Response Normalization を表します。
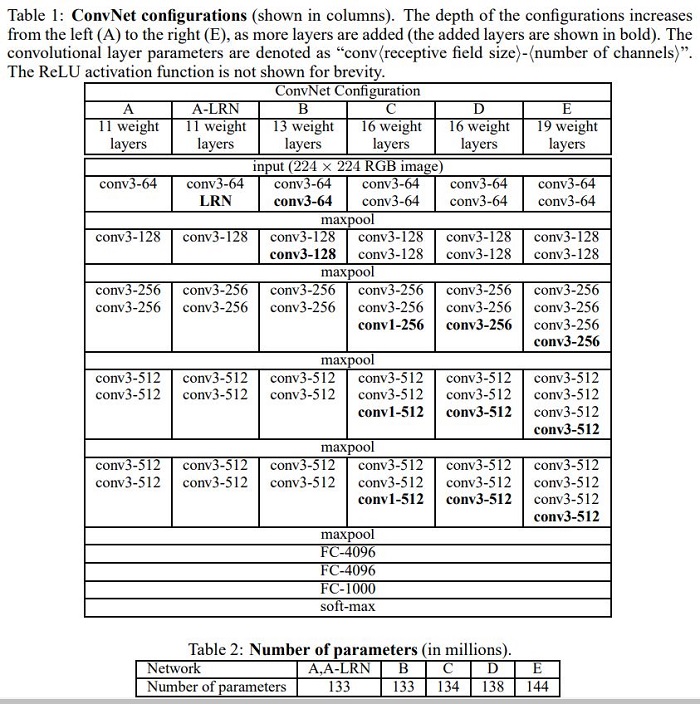
結果
- A と A-LRN で精度がほとんど変わらないため、LRN は効果がない上に計算量が増えるため、不要と判断しました。
- A < B < C, D < E の順で層が深いモデルほど精度が上がりました。
- C と D では D のほうが精度が高く、1×1 の畳み込みで非線形な変換するよりは、3×3 の畳み込みを追加して空間特徴量を抽出したほうが有用であるこがわかりました。
Pytorch の実装
- torchvision.models.vgg の実装を元に解説します。VGG が出た当時は Batch Normalization はありませんが、torchvision には、BatchNorm を入れたバージョンも用意されています。
特徴抽出部分
論文のパラメータ表の A、B、D、E それぞれの値を list で表現します。数値は畳み込み層の出力数、”M” はプーリング層を表しています。これを _make_layers() に渡して、特徴抽出部分を組み立てます。
cfgs = {
"A": [64, "M", 128, "M", 256, 256, "M", 512, 512, "M", 512, 512, "M"],
"B": [64, 64, "M", 128, 128, "M", 256, 256, "M", 512, 512, "M", 512, 512, "M"],
"D": [64, 64, "M", 128, 128, "M", 256, 256, 256, "M", 512, 512, 512, "M", 512, 512, 512, "M"],
"E": [64, 64, "M", 128, 128, "M", 256, 256, 256, 256, "M", 512, 512, 512, 512, "M", 512, 512, 512, 512, "M"],
}クラス分類部分
入力サイズが (224, 224) の場合、特徴抽出部の出力は (512, 7, 7) になっています。AdaptiveAvgPool2d((7, 7)) は、入力が (224, 224) より大きい場合に畳み込み層に渡す形状を (512, 7, 7) にダウンサンプリングするためにあります。
出力数が 4096 の全結合層2つのあとに出力数がクラス数の全結合層があります。
- 活性化関数の直後に Dropout を入れます。
重みの初期化
論文の Section 3.1 に従い、以下のように初期化します。
we sampled the weights from a normal distribution with the zero mean and 10^-2 variance. The biases were initialised with zero. we found that it is possible to initialise the weights without pre-training by using the random initialisation procedure of Glorot & Bengio (2010)
- 畳み込み層のカーネルは $N(0, \sqrt{\frac{2}{\text{fan\_in}}})$ に従う乱数で初期化します。これは Pytorch の
nn.init.kaiming_normal_()で行えます。バイアスは0で初期化します。 - 全結合層の重みは $N(0, 0.01)$ に従う乱数で初期化し、バイアスは0で初期化します。
import torch
import torch.nn as nn
class VGG(nn.Module):
def __init__(
self,
cfg,
batch_norm=False,
num_classes=1000,
dropout=0.5,
):
super().__init__()
self.features = self._make_layers(cfg, batch_norm)
self.avgpool = nn.AdaptiveAvgPool2d((7, 7))
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(True),
nn.Dropout(p=dropout),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(p=dropout),
nn.Linear(4096, num_classes),
)
self._initialize_weights()
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode="fan_out", nonlinearity="relu")
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
def _make_layers(self, cfg, batch_norm):
layers = []
in_channels = 3
for v in cfg:
if v == "M":
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
if batch_norm:
layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(True)]
else:
layers += [conv2d, nn.ReLU(True)]
in_channels = v
return nn.Sequential(*layers)
# fmt: off
cfgs = {
"A": [64, "M", 128, "M", 256, 256, "M", 512, 512, "M", 512, 512, "M"],
"B": [64, 64, "M", 128, 128, "M", 256, 256, "M", 512, 512, "M", 512, 512, "M"],
"D": [64, 64, "M", 128, 128, "M", 256, 256, 256, "M", 512, 512, 512, "M", 512, 512, 512, "M"],
"E": [64, 64, "M", 128, 128, "M", 256, 256, 256, 256, "M", 512, 512, 512, 512, "M", 512, 512, 512, 512, "M"],
}
# fmt: ondef vgg11():
return VGG(cfgs["A"])
def vgg11():
return VGG(cfgs["A"], batch_norm=True)
def vgg13():
return VGG(cfgs["B"])
def vgg13_bn():
return VGG(cfgs["B"], batch_norm=True)
def vgg16():
return VGG(cfgs["D"])
def vgg16_bn():
return VGG(cfgs["D"], batch_norm=True)
def vgg19():
return VGG(cfgs["E"])
def vgg19_bn():
return VGG(cfgs["E"], batch_norm=True)モデル一覧
| モデル名 | 関数名 | パラメータ数 | Top-1 エラー率 | Top-5 エラー率 |
|---|---|---|---|---|
| VGG-11 | vgg11() | 132863336 | 30.98 | 11.37 |
| VGG-13 | vgg13() | 133047848 | 30.07 | 10.75 |
| VGG-16 | vgg16() | 138357544 | 28.41 | 9.62 |
| VGG-19 | vgg19() | 143667240 | 27.62 | 9.12 |
| VGG-11 with batch normalization | vgg11_bn() | 132868840 | 29.62 | 10.19 |
| VGG-13 with batch normalization | vgg13_bn() | 133053736 | 28.45 | 9.63 |
| VGG-16 with batch normalization | vgg16_bn() | 138365992 | 26.63 | 8.5 |
| VGG-19 with batch normalization | vgg19_bn() | 143678248 | 25.76 | 8.15 |
コメント