
概要
YOLOv3 で独自のデータセットを学習する方法について解説します。本記事では、例として金魚の物体検出を学習します。 人や車など一部の物体は、自分で学習しなくとも配布されている MSCOCO の学習済みデータセットを使用すると検出できます。学習済みデータセットを使って推論する方法は以下の記事を参考にしてください。
[blogcard url=”https://pystyle.info/pytorch-yolov3-how-to-use-pretrained-model”]
動作確認環境
以下の環境で動作確認しました。バージョンは合わせなくとも最新の Pytorch が動く環境であれば大丈夫です。 GPU が使えない環境でも動作はしますが、学習の場合はかなり時間がかかるので、基本的には GPU が搭載された PC で CUDA 及び CuDNN が適切にセットアップされた環境で学習することをおすすめします。
- Ubuntu 18.04
- Nvidia ドライバ: 450.119.03
- CUDA: 10.2
- cuDNN: 7
- torch: 1.10.0
- torchvision: 0.11.1
YOLOv3 のスクリプトを準備する
YOLOv3 の Pytorch 実装である nekobean/pytorch_yolov3 を使用します。
まず、レポジトリをクローンします。
git clone https://github.com/nekobean/pytorch_yolov3.git
cd pytorch_yolov3依存ライブラリをインストールします。
pip install -r requirements.txt古いバージョンの Pytorch がインストールされている場合は、次のコマンドで最新バージョンに更新してください。
pip install -U torch torchvision torchaudioDarknet 53 の学習済みの重み darknet53.conv.74 をダウンロードします。物体検出の学習は転移学習の形で行うので、この重みが必要となります。
wget https://pjreddie.com/media/files/darknet53.conv.74ダウンロードが完了したら、weights ディレクトリに配置してください。
weights/
|-- download_weights.sh
`-- darknet53.conv.74Windows の場合、bash が使えないので、手動で darknet53.conv.74 をダウンロードして、weights/ ディレクトリに置いてください。
データセット作成
画像収集
アノテーションするための画像を用意します。検出対象物が一般的なものでない場合は自分で対象物を撮影するところから始めます。逆にネット上でも十分な枚数の画像が入手可能な場合は、Google 画像検索などを活用して画像を収集するとよいでしょう。 必要な枚数ですが、1クラスあたり最低300ラベルはあったほうがよいでしょう。枚数でなくラベル数なので、例えば、ある物体が1枚に3個写っていたとすると、3ラベルとカウントします。
google-images-download を使って、Google 検索結果から画像を保存する方法 – pystyle
今回は google-images-download を使って、Web 上から金魚の画像を414枚収集しました。
アノテーション
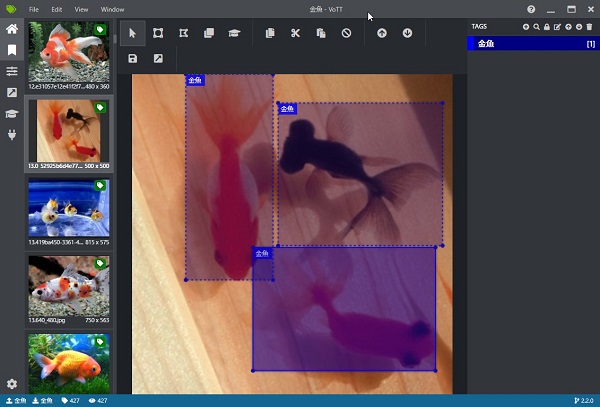
物体検出用のアノテーションツールを使って、画像に対して物体がある位置の注釈をつけるアノテーションを行います。本記事では VoTT というツールの使用を前提に解説します。他にも tzutalin/labelImg などいくつか種類があるので、使いやすいと思うものを使用してください。
物体検出のアノテーションツール VOTT の使い方 – pystyle
VOTT ですべての画像に対してアノテーションを行いました。414枚の画像に対して625ラベルのアノテーションを行い、作業時間は2時間でした。アノテーションは時間がかかる地道な作業ですが、精度を出すためにとても重要です。学習ではオーグメンテーションも行いますが、これにより機械的に増やせるバリエーションは照明や向きの変化などに限定されるので、多少の精度向上には寄与しますが、元々のデータ数が少ない場合はどうしようもありません。できるだけ沢山の画像を集めて、アノテーションをしましょう。
学習する
設定ファイルの準備
config/yolov3_custom.yamlのn_classesにクラス数を設定します。今回は1クラスなのでn_classes: 1としました。config/custom_classes.txtに1行に1つのクラスを記載します。
データセットの変換
スクリプトの都合上、VOTT でアノテーションしたデータセットを1枚の画像に対して、ラベルが記載された1つのテキストファイルが対応する以下の形式にデータセットを変換します。
python convert_vott_dataset.py <VOTT のデータセットのあるディレクトリ> <出力先のディレクトリ>例:
python convert_vott_dataset.py F:\work\dataset\金魚 custom_dataset変換が完了すると、<出力先のディレクトリ> ディレクトリに学習の際に与えるデータセットが出力されます。images に画像、labels に同じ名前で対応するラベルが配置されます。
custom_dataset
|-- train.txt: 学習に使用する画像のファイル名の一覧
|-- test.txt: テストに使用する画像のファイル名の一覧
|-- images
| |-- 000000.jpg
| |-- 000001.jpg
...
`-- labels
|-- 000000.txt
|-- 000001.txt
...今回サンプルとして使用した金魚のデータセットは custom_dataset.zip からダウンロードできます。
学習する
学習前に上記作業を行った時点での自作データセットに関係するファイルを確認します。以下これまでの作業のチェック項目になります。
- レポジトリをダウンロードする
pipで依存ライブラリをインストールするdarknet53.conv.74をダウンロードして、weights以下に配置するcustom_classes.txtにクラス名の一覧を設定するyolov3_custom.yamlのn_classesにクラス数を設定する- VOTT でアノテーションを行い、
convert_vott_dataset.pyでデータセットを変換する
pytorch_yolov3
|-- config
| |-- custom_classes.txt ← クラスの一覧を設定
| `-- yolov3_custom.yaml ← クラス数 n_classes を設定
|-- custom_dataset ← データセット
| |-- images
| | |-- 000000.jpg
| | |-- 000001.jpg
| ...
| `-- labels
| |-- 000000.txt
| |-- 000001.txt
| ...
`-- weights
`-- darknet53.conv.74 ← ダウンロードした Darknet 53 の学習済みの重みこのようなディレクトリ構成になっていることが確認できたら、以下のコマンドで学習を開始します。
--dataset_dir: 上記データセットのディレクトリパス--weights: 学習済みモデルのパス。(YOLOv3 の場合、weights/darknet53.conv.74を指定する。)--config: 設定ファイルのパス
python train_custom.py --dataset_dir custom_dataset --weights weights/darknet53.conv.74 --config config/yolov3_custom.yaml学習結果は train_output というディレクトリが作られ、その中に重みを含む学習途中の状態が .ckpt ファイル、損失の履歴が .csv に保存されます。すべての学習が完了すると重みファイル yolov3_final.pth が保存されます。
`-- train_output
|-- yolov3_001000.ckpt
|-- yolov3_001000.csv
|-- yolov3_002000.ckpt
|-- yolov3_002000.csv
|-- ...
|-- yolov3_final.pth
`-- yolov3_final.csv- 学習時間は使用している GPU の性能に依存します。参考として、Pascal TITAN X で10000ステップの学習が完了するのに8時間かかりました。
- 学習に必要なステップ数はデータセットの規模によって異なります。変更したい場合は、下記の「設定ファイルのカスタマイズ」の項目を参考に
yolov3_custom.yamlを編集してください。 - 推論は学習途中の .ckpt ファイルまたは重み .pth ファイルの両方が使用できます。
学習完了後に損失関数の推移が記載された history.csv を pandas で読み込み、グラフ化してみます。
import pandas as pd
from matplotlib import pyplot as plt
df = pd.read_csv("train_output/history.csv")
df.plot(
x="iter",
y=["loss_total", "loss_xy", "loss_wh", "loss_obj", "loss_cls"],
figsize=(8, 4),
logy=True,
)
plt.show()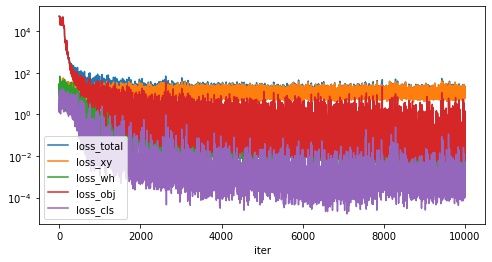
学習を途中から再開する
train_output 以下に学習途中の状態が記録された yolov3_<ステップ数>.ckpt が生成されます。何ステップごとに保存するかは --save_interval <保存間隔> で指定でき、デフォルトでは1000ステップごとに保存されるようになっています。学習を途中から再開したい場合は train_custom.py の引数 --weights 引数に .ckpt ファイルのパスを指定してください。
python train_custom.py --dataset_dir custom_dataset --weights <.ckpt ファイルのパス> --config config/yolov3_custom.yaml例
python train_custom.py --dataset_dir custom_dataset --weights yolov3_001000.ckpt --config config/yolov3_custom.yaml設定ファイルのカスタマイズ
yolov3_custom.yaml のうち、カスタマイズできる項目をピックアップしました。
train/max_iterで最大ステップ数を変更できます。その際、学習率を減衰するタイミングであるtrain/stepsの値を[max_iter * 0.8, max_iter * 0.9]に合わせて変更してください。test/img_sizeは推論時の入力サイズです。大きいほど精度が高くなりますが、その分計算量が増えるので速度が低下します。YOLOv3 の制約上、[320, 352, 384, 416, 448, 480, 512, 544, 576, 608]の中から選択してください。test/conf_thresholdは推論時のスコアの閾値です。このスコア未満の検出結果は無視されます。
model:
n_classes: クラス数
train:
steps: [8000, 9000] # 学習率を減衰されるタイミング [max_iter * 0.8, max_iter * 0.9] に設定するのを推奨
max_iter: 10000 # 最大ステップ数
batch_size: 4 # 学習時のバッチサイズ
test:
batch_size: 32 # 学習時のバッチサイズ
conf_threshold: 0.5 # スコアの閾値、このスコア未満の検出結果は無視する
nms_threshold: 0.45 # Non Maximum Suppression の閾値
img_size: 416 # 推論時の入力画像サイズを [320, 352, 384, 416, 448, 480, 512, 544, 576, 608] の中から指定する。学習した重みで推論する
学習した重みを使用して、金魚の画像に対して推論してみます。出力結果は output ディレクトリ以下に出力されます。
--input: 推論する画像ファイルのパス--output: 結果を出力するディレクトリのパス--weights: 学習した重みファイルのパス (.pthファイルまたは学習途中の.ckptファイル)--config: 設定ファイルのパス
python detect_image.py --input goldfish.jpg --output output --weights train_output/yolov3_final.pth --config config/yolov3_custom.yaml
output に推論結果が保存されます。画像にうつっている金魚が正しく検出できました。
学習した重みを自分のプログラムで使う
学習した重みを使った検出をスクリプトではなく、自分のプログラムで行いたい場合のサンプルコードを以下に記載します。
import sys
from pathlib import Path
import cv2
from IPython.display import Image, display
# 以下の3つのパスは適宜変更してください
yolov3_path = Path("../pytorch_yolov3") # git clone した pytorch_yolov3 ディレクトリのパスを指定してください。
config_path = yolov3_path / "config/yolov3_custom.yaml" # yolov3_custom.yaml のパスを指定してください
weights_path = yolov3_path / "train_output/yolov3_final.pth" # 重みのパスを指定してください
sys.path.append(str(yolov3_path))
from yolov3.detector import Detector
def imshow(img):
"""ndarray 配列をインラインで Notebook 上に表示する。"""
ret, encoded = cv2.imencode(".jpg", img)
display(Image(encoded))
# 検出器を作成する。
detector = Detector(config_path, weights_path)
# 画像を読み込む。
img = cv2.imread("sample.jpg")
# 検出する。
detection = detector.detect_from_imgs(img)[0]
# 検出結果を画像に描画する。
for bbox in detection:
cv2.rectangle(
img,
(int(bbox["x1"]), int(bbox["y1"])),
(int(bbox["x2"]), int(bbox["y2"])),
color=(0, 255, 0),
thickness=2,
)
imshow(img)Checkpoint file ../pytorch_yolov3/train_output/yolov3_final.pth loaded.

学習した重みを評価する
学習した重みを使用して、物体検出の評価に使われる AP (Pascal VOC の定義) を計算します。詳細については以下を参照してください。
[blogcard url=”https://pystyle.info/how-to-calculate-object-detection-metrics-map”]
--dataset_dir: データセットのディスプレイパス (学習に使用したものと同じディレクトリ)--weights: 学習した重みファイルのパス (.pthファイルまたは学習途中の.ckptファイル)--config: 設定ファイルのパス--iou: 評価する際の IOU の閾値。デフォルトは 0.5。
評価対象のサンプルは、データセットのディレクトリのうち、学習に使用していない <dataset_dir>/test.txt に記載された画像ファイルが対象になります。
python evaluate_custom.py --dataset_dir custom_dataset --weights train_output/yolov3_final.pth --config config/yolov3_custom.yaml --out 0.5実行すると、metrics_output 以下に評価結果が出力されます。
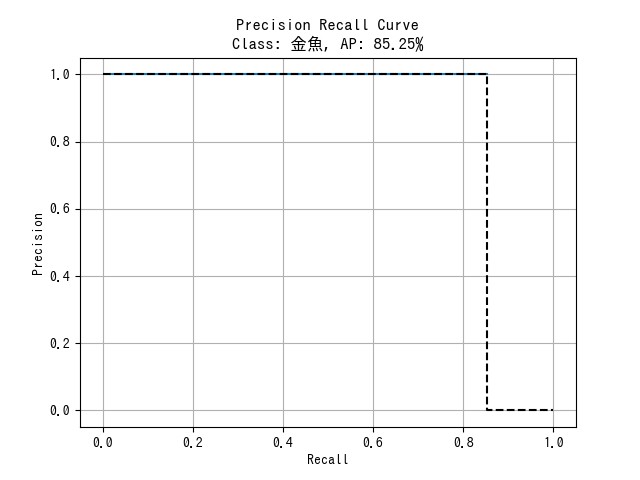
metrics.csv: クラスごとの AP 及び mAP
| Class | AP |
|---|---|
| 金魚 | 0.8524590163934426 |
| mAP | 0.8524590163934426 |
<クラス名>.png: クラスごとの PR 曲線
コメント
コメント一覧 (0件)
はじめましてとある大学院生です。
当サイトを拝見させていただいているのですが,非常にわかりやすくとても助かっております。
実際に当サイトでのデータセットで実行してみたところしっかりと学習出来きていることを確認することができました。
そこで自作のデータセットで学習を行ったところ
raise ValueError(
# “Expected {name} for bbox {bbox} ”
# “to be in the range [0.0, 1.0], got {value}.”.format(bbox=bbox, name=name, value=value)
というエラーがでてしまいました。きちんと正規化ができていない、もしくはデータセットの座標がおかしいかもしれないと考え,自分なりに確認したのですがデータセットはおかしくないようで困っております。
また,上記のエラーが出ても学習を続行せさて,得られた重みを評価しようとしたところ以下のようなエラーが出てしまいました。
size mismatch for module_list.35.conv.bias: copying a param with shape torch.Size([18]) from checkpoint, the shape in current model is torch.Size([21]).
自分でもいろいろと確認や調べているのですが,解決できず困っております。もしよろしければ,アドバイス等いただけると幸いです。
コメントありがとうございます。
ライブラリのアップデート等の影響があるかもしれないので確認しようと思います。返信は数日お時間をいただくかもしれません。
ご返信ありがとうございます。
本当にありがとうございます。
自分でも解決方法の模索を続けたいと思います。
本日確認しましたが、現在の Pytorch でも動作しました。
自作したデータセットはどのような手順で作成されましたか?
本記事では VOTT というアノテーションツールで作成したものを https://github.com/nekobean/pytorch_yolov3 の convert_vott_dataset.py で変換するやり方で紹介しています。
学習スクリプトの入力となるデータセットもこのやり方で作成されたものを前提としています。
レポジトリにサンプルのデータセット custom_dataset.zip がございますので、以下の形式になっているか確認してみてください。
https://github.com/nekobean/pytorch_yolov3/raw/main/custom_dataset.zip
custom_dataset
|– images
| |– 000000.jpg
| |– 000001.jpg
| …
| — labels
| |– 000000.txt
| |– 000001.txt
|– train.txt
`– test.txt
丁寧なご返信ありがとうございます。
自分でデータセットを確認したところ一枚の画像のせいでエラーになっていることがわかり、その画像を取り除いたところ問題なくじっこうすることができました。
ありがとうございました。
当サイトを拝見させていただきましたが、他のどのサイトよりも分かりやすく非常にタメになりました。
少しお聞きしたいのですが、複数のラベルで学習する際はどのようにしたらよいでしょうか?imagesとlabelsディレクトリに全ラベルのもを入れてたら良いのですか?
また、複数のラベルで学習することで精度が落ちてしまうことはありますか?
その他で複数のラベルを用いて学習する際に注意する点やポイントがあれば教えていただけると幸いです。
コメントありがとうございます。
> 複数のラベルで学習する際はどのようにしたらよいでしょうか?imagesとlabelsディレクトリに全ラベルのもを入れてたら良いのですか?
「複数のラベル」というのは、1つの画像に検出対象である異なるクラスの物体が複数あり、それぞれアノテーションされているということでしょうか?
当サイトで紹介しているスクリプトの入力となるデータセットにの仕様は、images ディレクトリに画像ファイル、labels ディレクトリに対応するラベルが記載された同名のファイルがあるという想定です。
custom_dataset
|– images
| |– 000000.jpg
| |– 000001.jpg
| …
| — labels
| |– 000000.txt
| |– 000001.txt
|– train.txt
`– test.txt
ラベルファイルは1行に1つの物体の座標及びクラスを記述します。1つの画像に複数の物体がある場合は以下のように複数行になります。
“`
xmin ymin xmax ymax クラス
xmin ymin xmax ymax クラス
“`
> 複数のラベルで学習することで精度が落ちてしまうことはありますか?
とくにないですが、データ数が十分にないクラスの精度は低くなります。
管理者様
以前に質問させていただいたnobuでございます。
おかげさまで、物体検出を実務では使いこなせるようになりました。
そこで基本的なことを見返しているのですが、nms_threshold(yolov5ではiou_thres)についてご質問があります。
正解ボックスと予測ボックスの重なり率ということと、予測ボックスについては理解できるのですが、基準となる正解ボックスはどのようにして設定されるのでしょうか。
画像のどの位置に正解ボックスが存在しているのかは不明、と理解しており、nms_thresholdの算出方法が分からないという状況です。
基本的なことで恐縮ですが、ご教授いただけると幸いです。
コメントありがとうございます。
学習時の nms_threshold についての質問でしょうか。
YOLOv5 は詳しく知らないため、YOLOv3 の仕組みを前提に説明します。
正解の矩形は、アノテーションされている矩形です。
学習時は、モデルが出力した予測した矩形が正解かどうかを判定するのに、「正解の矩形とラベルが合っている」かつ「正解の矩形との IOU が nms_threshold 以上」という条件を満たす場合、正解と判定します。
IOU は重なり度合いのことで、値が大きいほど重なっていることを意味し、つまり、正解の矩形とラベルが合っていて、矩形もおおよそ一致している場合は正解と判定するということです。
ちなみに、推論時は一つの物体に対して複数の矩形が出力されるので、Non Maximum Supression (NMS) を行い、1つの矩形に統合します。
NMS を実行する際にも nms_threshold のパラメータを使用しますが、学習時のパラメータとは別物です。
https://pystyle.info/opencv-non-maximum-suppression/
この記事で使用しているコードでは、学習時の nms_threshold は、ignore_threshold、推論時の NMS に使用するパラメータは nms_threshold という名前にしています。
https://github.com/nekobean/pytorch_yolov3/blob/main/config/yolov3_coco.yaml
管理者様
学習時と推論時で考え方が違うこと、よくわかりました。
そこからして、認識が間違っておりました。
ありがとうございました。