
概要
YOLOv3 で独自のデータセットを学習する方法について解説します。本記事では、例として金魚の物体検出を学習します。 人や車など一部の物体は、自分で学習しなくとも配布されている MSCOCO の学習済みデータセットを使用すると検出できます。学習済みデータセットを使って推論する方法は以下の記事を参考にしてください。
[blogcard url=”https://pystyle.info/pytorch-yolov3-how-to-use-pretrained-model”]
動作確認環境
以下の環境で動作確認しました。バージョンは合わせなくとも最新の Pytorch が動く環境であれば大丈夫です。 GPU が使えない環境でも動作はしますが、学習の場合はかなり時間がかかるので、基本的には GPU が搭載された PC で CUDA 及び CuDNN が適切にセットアップされた環境で学習することをおすすめします。
- Ubuntu 18.04
- Nvidia ドライバ: 450.119.03
- CUDA: 10.2
- cuDNN: 7
- torch: 1.10.0
- torchvision: 0.11.1
YOLOv3 のスクリプトを準備する
YOLOv3 の Pytorch 実装である nekobean/pytorch_yolov3 を使用します。
まず、レポジトリをクローンします。
git clone https://github.com/nekobean/pytorch_yolov3.git
cd pytorch_yolov3依存ライブラリをインストールします。
pip install -r requirements.txt古いバージョンの Pytorch がインストールされている場合は、次のコマンドで最新バージョンに更新してください。
pip install -U torch torchvision torchaudioDarknet 53 の学習済みの重み darknet53.conv.74 をダウンロードします。物体検出の学習は転移学習の形で行うので、この重みが必要となります。
wget https://pjreddie.com/media/files/darknet53.conv.74ダウンロードが完了したら、weights ディレクトリに配置してください。
weights/
|-- download_weights.sh
`-- darknet53.conv.74Windows の場合、bash が使えないので、手動で darknet53.conv.74 をダウンロードして、weights/ ディレクトリに置いてください。
データセット作成
画像収集
アノテーションするための画像を用意します。検出対象物が一般的なものでない場合は自分で対象物を撮影するところから始めます。逆にネット上でも十分な枚数の画像が入手可能な場合は、Google 画像検索などを活用して画像を収集するとよいでしょう。 必要な枚数ですが、1クラスあたり最低300ラベルはあったほうがよいでしょう。枚数でなくラベル数なので、例えば、ある物体が1枚に3個写っていたとすると、3ラベルとカウントします。
google-images-download を使って、Google 検索結果から画像を保存する方法 – pystyle
今回は google-images-download を使って、Web 上から金魚の画像を414枚収集しました。
アノテーション
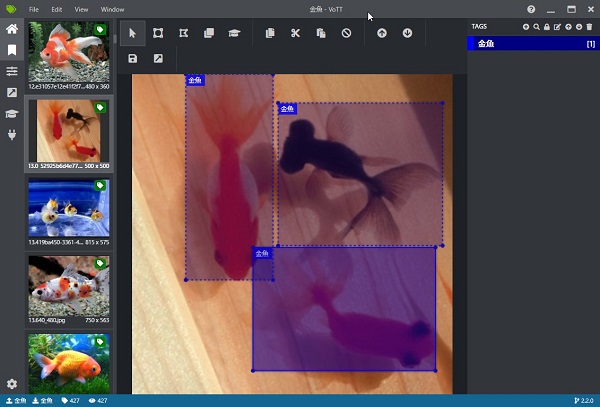
物体検出用のアノテーションツールを使って、画像に対して物体がある位置の注釈をつけるアノテーションを行います。本記事では VoTT というツールの使用を前提に解説します。他にも tzutalin/labelImg などいくつか種類があるので、使いやすいと思うものを使用してください。
物体検出のアノテーションツール VOTT の使い方 – pystyle
VOTT ですべての画像に対してアノテーションを行いました。414枚の画像に対して625ラベルのアノテーションを行い、作業時間は2時間でした。アノテーションは時間がかかる地道な作業ですが、精度を出すためにとても重要です。学習ではオーグメンテーションも行いますが、これにより機械的に増やせるバリエーションは照明や向きの変化などに限定されるので、多少の精度向上には寄与しますが、元々のデータ数が少ない場合はどうしようもありません。できるだけ沢山の画像を集めて、アノテーションをしましょう。
学習する
設定ファイルの準備
config/yolov3_custom.yamlのn_classesにクラス数を設定します。今回は1クラスなのでn_classes: 1としました。config/custom_classes.txtに1行に1つのクラスを記載します。
データセットの変換
スクリプトの都合上、VOTT でアノテーションしたデータセットを1枚の画像に対して、ラベルが記載された1つのテキストファイルが対応する以下の形式にデータセットを変換します。
python convert_vott_dataset.py <VOTT のデータセットのあるディレクトリ> <出力先のディレクトリ>例:
python convert_vott_dataset.py F:\work\dataset\金魚 custom_dataset変換が完了すると、<出力先のディレクトリ> ディレクトリに学習の際に与えるデータセットが出力されます。images に画像、labels に同じ名前で対応するラベルが配置されます。
custom_dataset
|-- train.txt: 学習に使用する画像のファイル名の一覧
|-- test.txt: テストに使用する画像のファイル名の一覧
|-- images
| |-- 000000.jpg
| |-- 000001.jpg
...
`-- labels
|-- 000000.txt
|-- 000001.txt
...今回サンプルとして使用した金魚のデータセットは custom_dataset.zip からダウンロードできます。
学習する
学習前に上記作業を行った時点での自作データセットに関係するファイルを確認します。以下これまでの作業のチェック項目になります。
- レポジトリをダウンロードする
pipで依存ライブラリをインストールするdarknet53.conv.74をダウンロードして、weights以下に配置するcustom_classes.txtにクラス名の一覧を設定するyolov3_custom.yamlのn_classesにクラス数を設定する- VOTT でアノテーションを行い、
convert_vott_dataset.pyでデータセットを変換する
pytorch_yolov3
|-- config
| |-- custom_classes.txt ← クラスの一覧を設定
| `-- yolov3_custom.yaml ← クラス数 n_classes を設定
|-- custom_dataset ← データセット
| |-- images
| | |-- 000000.jpg
| | |-- 000001.jpg
| ...
| `-- labels
| |-- 000000.txt
| |-- 000001.txt
| ...
`-- weights
`-- darknet53.conv.74 ← ダウンロードした Darknet 53 の学習済みの重みこのようなディレクトリ構成になっていることが確認できたら、以下のコマンドで学習を開始します。
--dataset_dir: 上記データセットのディレクトリパス--weights: 学習済みモデルのパス。(YOLOv3 の場合、weights/darknet53.conv.74を指定する。)--config: 設定ファイルのパス
python train_custom.py --dataset_dir custom_dataset --weights weights/darknet53.conv.74 --config config/yolov3_custom.yaml学習結果は train_output というディレクトリが作られ、その中に重みを含む学習途中の状態が .ckpt ファイル、損失の履歴が .csv に保存されます。すべての学習が完了すると重みファイル yolov3_final.pth が保存されます。
`-- train_output
|-- yolov3_001000.ckpt
|-- yolov3_001000.csv
|-- yolov3_002000.ckpt
|-- yolov3_002000.csv
|-- ...
|-- yolov3_final.pth
`-- yolov3_final.csv- 学習時間は使用している GPU の性能に依存します。参考として、Pascal TITAN X で10000ステップの学習が完了するのに8時間かかりました。
- 学習に必要なステップ数はデータセットの規模によって異なります。変更したい場合は、下記の「設定ファイルのカスタマイズ」の項目を参考に
yolov3_custom.yamlを編集してください。 - 推論は学習途中の .ckpt ファイルまたは重み .pth ファイルの両方が使用できます。
学習完了後に損失関数の推移が記載された history.csv を pandas で読み込み、グラフ化してみます。
import pandas as pd
from matplotlib import pyplot as plt
df = pd.read_csv("train_output/history.csv")
df.plot(
x="iter",
y=["loss_total", "loss_xy", "loss_wh", "loss_obj", "loss_cls"],
figsize=(8, 4),
logy=True,
)
plt.show()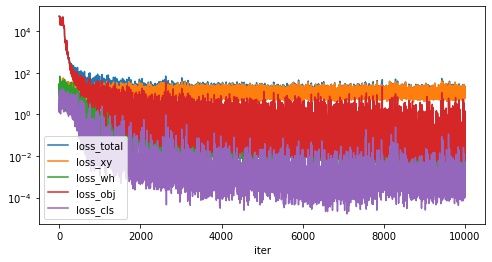
学習を途中から再開する
train_output 以下に学習途中の状態が記録された yolov3_<ステップ数>.ckpt が生成されます。何ステップごとに保存するかは --save_interval <保存間隔> で指定でき、デフォルトでは1000ステップごとに保存されるようになっています。学習を途中から再開したい場合は train_custom.py の引数 --weights 引数に .ckpt ファイルのパスを指定してください。
python train_custom.py --dataset_dir custom_dataset --weights <.ckpt ファイルのパス> --config config/yolov3_custom.yaml例
python train_custom.py --dataset_dir custom_dataset --weights yolov3_001000.ckpt --config config/yolov3_custom.yaml設定ファイルのカスタマイズ
yolov3_custom.yaml のうち、カスタマイズできる項目をピックアップしました。
train/max_iterで最大ステップ数を変更できます。その際、学習率を減衰するタイミングであるtrain/stepsの値を[max_iter * 0.8, max_iter * 0.9]に合わせて変更してください。test/img_sizeは推論時の入力サイズです。大きいほど精度が高くなりますが、その分計算量が増えるので速度が低下します。YOLOv3 の制約上、[320, 352, 384, 416, 448, 480, 512, 544, 576, 608]の中から選択してください。test/conf_thresholdは推論時のスコアの閾値です。このスコア未満の検出結果は無視されます。
model:
n_classes: クラス数
train:
steps: [8000, 9000] # 学習率を減衰されるタイミング [max_iter * 0.8, max_iter * 0.9] に設定するのを推奨
max_iter: 10000 # 最大ステップ数
batch_size: 4 # 学習時のバッチサイズ
test:
batch_size: 32 # 学習時のバッチサイズ
conf_threshold: 0.5 # スコアの閾値、このスコア未満の検出結果は無視する
nms_threshold: 0.45 # Non Maximum Suppression の閾値
img_size: 416 # 推論時の入力画像サイズを [320, 352, 384, 416, 448, 480, 512, 544, 576, 608] の中から指定する。学習した重みで推論する
学習した重みを使用して、金魚の画像に対して推論してみます。出力結果は output ディレクトリ以下に出力されます。
--input: 推論する画像ファイルのパス--output: 結果を出力するディレクトリのパス--weights: 学習した重みファイルのパス (.pthファイルまたは学習途中の.ckptファイル)--config: 設定ファイルのパス
python detect_image.py --input goldfish.jpg --output output --weights train_output/yolov3_final.pth --config config/yolov3_custom.yaml
output に推論結果が保存されます。画像にうつっている金魚が正しく検出できました。
学習した重みを自分のプログラムで使う
学習した重みを使った検出をスクリプトではなく、自分のプログラムで行いたい場合のサンプルコードを以下に記載します。
import sys
from pathlib import Path
import cv2
from IPython.display import Image, display
# 以下の3つのパスは適宜変更してください
yolov3_path = Path("../pytorch_yolov3") # git clone した pytorch_yolov3 ディレクトリのパスを指定してください。
config_path = yolov3_path / "config/yolov3_custom.yaml" # yolov3_custom.yaml のパスを指定してください
weights_path = yolov3_path / "train_output/yolov3_final.pth" # 重みのパスを指定してください
sys.path.append(str(yolov3_path))
from yolov3.detector import Detector
def imshow(img):
"""ndarray 配列をインラインで Notebook 上に表示する。"""
ret, encoded = cv2.imencode(".jpg", img)
display(Image(encoded))
# 検出器を作成する。
detector = Detector(config_path, weights_path)
# 画像を読み込む。
img = cv2.imread("sample.jpg")
# 検出する。
detection = detector.detect_from_imgs(img)[0]
# 検出結果を画像に描画する。
for bbox in detection:
cv2.rectangle(
img,
(int(bbox["x1"]), int(bbox["y1"])),
(int(bbox["x2"]), int(bbox["y2"])),
color=(0, 255, 0),
thickness=2,
)
imshow(img)Checkpoint file ../pytorch_yolov3/train_output/yolov3_final.pth loaded.

学習した重みを評価する
学習した重みを使用して、物体検出の評価に使われる AP (Pascal VOC の定義) を計算します。詳細については以下を参照してください。
[blogcard url=”https://pystyle.info/how-to-calculate-object-detection-metrics-map”]
--dataset_dir: データセットのディスプレイパス (学習に使用したものと同じディレクトリ)--weights: 学習した重みファイルのパス (.pthファイルまたは学習途中の.ckptファイル)--config: 設定ファイルのパス--iou: 評価する際の IOU の閾値。デフォルトは 0.5。
評価対象のサンプルは、データセットのディレクトリのうち、学習に使用していない <dataset_dir>/test.txt に記載された画像ファイルが対象になります。
python evaluate_custom.py --dataset_dir custom_dataset --weights train_output/yolov3_final.pth --config config/yolov3_custom.yaml --out 0.5実行すると、metrics_output 以下に評価結果が出力されます。
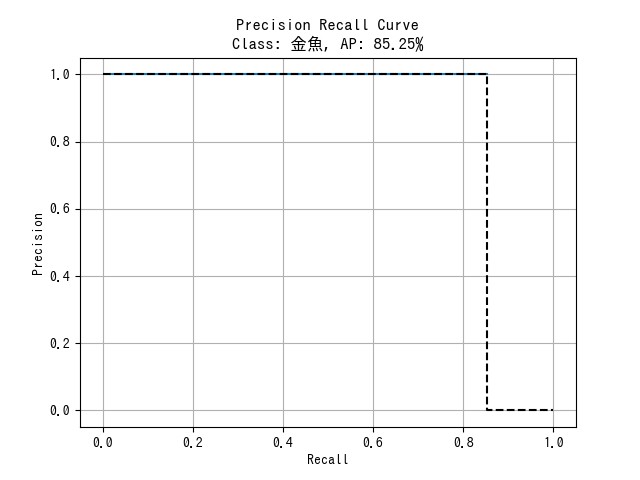
metrics.csv: クラスごとの AP 及び mAP
| Class | AP |
|---|---|
| 金魚 | 0.8524590163934426 |
| mAP | 0.8524590163934426 |
<クラス名>.png: クラスごとの PR 曲線
コメント
コメント一覧 (0件)
AttributeError: module ‘ops’ has no attribute ‘nms’
というエラーが出るのですが,ライブラリのバージョンを教えていただいても良いでしょうか?
コメントありがとうございます。
推論時に重複する矩形を削除するために torchvision.ops.nms() で Non Maximum Suppression を行っています。
https://pytorch.org/vision/stable/ops.html
記事執筆時の torchvision のバージョンは 0.9.1 でした。
現在の最新版 0.10.0 でも動きましたので、もし torchvision のバージョンが古いようでしたら、以下のコマンドでアップデートを試してみてください。
torchvision のバージョンを確認
pip show torchvision
torchvision のアップデート
pip install -U torchvision
ご説明ありがとうございます!
返信を見る前に外部からnms関数を移植することで解決しましたが,教えていただいた方法でも試してみます!
↑推論を行う際,utils.pyで起こります.
管理者様、貴重な情報ありがとうございます。
下記URLを参考にして、学習済みモデルを使って検出することは成功しました(とても感謝です)。
https://pystyle.info/pytorch-yolov3-how-to-use-pretrained-model/
そこで、新規に画像を集めて自作データセットの学習を始めたのですが、下記のエラー「KeyError:’yolov3’」が表示され、なかなか解決しない状況です。
File “C:\Users\walse\_python_data\画像編集vott\パラグライダー\train_custom.py”, line 10, in
from yolov3.datasets.custom import CustomDataset
KeyError: ‘yolov3’
対処方法がありましたら、ご教授いただけると幸いです。
当方の環境は下記です。
Python3.6(3.8だとtensorflowのバージョン関係で動かない)
numpy1.19.4
tensorflow1.14.0
よろしくお願いします。
コメントありがとうございます。
「パラグライダ」という名前のディレクトリ以下に train_custom.py がございますが、このディレクトリは pytorch_yolov3 をリネームしたものでしょうか?
Windows 環境で確認しましたが、エラーが再現しませんでした。
スクリプトを実行する際のカレントディレクトリは pytorch_yolov3 ディレクトリになっておりますでしょうか?
もしなっていないようであれば、スクリプト実行前に cd コマンドで pytorch_yolov3 ディレクトリにカレントディレクトリを変更してみてください。
1. コマンドプロンプトを起動
2. cd [pytorch_yolov3 ディレクトリのパス] でカレントディレクトリを変更
現在のカレントディレクトリは引数なしで cd とだけ打ては確認できます。
> 3.8だとtensorflowのバージョン関係で動かない
本プログラム https://github.com/nekobean/pytorch_yolov3 は Pytorch で実装しているため、TensorFlow は使用していないため、TensorFlow がインストールされていない環境でも Pytorch が使えれば動作します。
—————————–
差し支えなければ、スタックトレースを全部貼っていただけるともう少し詳しいことがわかるかもしれません。
管理者様
コマンドプロンプトで実行したところ、正常に流れました。
いつも Spyderで計算しており、上記のKeyErrorは、Spyderで実行した場合の表示でした(原因は分かりませんでした)。
あと、「3.8だとtensorflowのバージョン関係で動かない」というのは、学習済みモデルで物体検出する時の現象でした(間違った情報で申し訳ありません)。
おかげさまで、大変助かりました。
感謝いたします。
管理人様、yolov3と自作データセットを使った画像検出技術に関する情報提供、ありがとうございます。
私はgooglecolabでこのページで紹介されている方法に沿って画像検出を行っており、googlecolabの環境でも正常に動作しました。
しかし、googlecolabは1日に使用できるGPUの使用量が限られており、学習する際は全10000段階のうち、1日に1000以上2000以下までしか学習できません。
1000段階でチェックポイントとして出力される重みでも推論は十分可能ですが、精度としてはまだ怪しいところがあります。
現在、1000段階でのチェックポイントから学習を再開する方法を探していますが、まだ見つかりません。
もしチェックポイントから学習を再開する方法をご存知でしたらご教授していただけると幸いです。
お忙しいところ大変ご不便をおかけしますが、よろしくお願いいたします。
コメントありがとうございます。
> もしチェックポイントから学習を再開する方法をご存知でしたらご教授していただけると幸いです。
途中から学習を再開できるように GitHub にあるプログラムを修正するので、少々お待ち下さい。
コードと記事の内容を更新しました。
学習途中の状態が train_output/ 以下に .ckpt ファイルとして保存されるようにしたので、このファイルを –weights 引数に指定することで学習途中から再開できるようにしました。保存間隔はデフォルトで1000イテレーションごととなっておりますが、`–save_interval` 引数で変更できます。
作成済みのデータセットのディレクトリは引き続き利用できますが、スクリプト .py や設定ファイル yolov3_custom.yaml が一部変わりましたので、https://github.com/nekobean/pytorch_yolov3 から最新版のものを取得してお使いください。
学習を途中から再開する例
“`
python train_custom.py –dataset_dir custom_dataset –weights train_output/yolov3_001000.ckpt –config config/yolov3_custom.yaml –save_interval 1000
“`
学習するイテレーション数ですが、データセットが小規模なら1万回未満でもそれなりの精度が出るとは思いますが、YOLO の仕様上、最初の1000イテレーションは burn_in フェーズといって学習率が低くなっており、あまり重みが調整されないため、少なくとも2000~3000ぐらいは学習を回したほうがいいと思われます。最大イテレーション数は `yolov3_custom.yaml` の max_iter で変更できます。
matuso2506です。
この度はお忙しい中、早急なご対応とご返信ありがとうございます。
夜分遅くまでコードとサイトの更新をしてくださり、心より感謝申し上げます。
早速、最新版を私の環境で動作させてみますので、もし不明点があった場合は再度返信させていただいます。
ありがとうございました。
先日、学習を途中から再開させる方法をお尋ねしたmatuso2506です。
学習を1000イテレーションから再開しようとしましたが、下記のエラーが出ました。
python train_custom.py –dataset_dir custom_dataset –weights train_output/yolov3_001000.ckpt –config config/yolov3_custom.yaml
↓
Checkpoint file train_output/yolov3_001000.ckpt loaded.
Traceback (most recent call last):
File “train_custom.py”, line 243, in
main()
File “train_custom.py”, line 160, in main
history = state[“history”]
KeyError: ‘history’
エラーが出ているtrain_custom.pyの160行目の history = state[“history”] の文を消すと正常に学習が1001から再開されますが、消しても問題ありませんか?
もし問題があるようであれば対処法をご教授していただきたく存じます。
よろしくお願いいたします。
> train_custom.pyの160行目の history = state[“history”] の文を消すと正常に学習が1001から再開されますが、消しても問題ありませんか?
すいません、チェックポイントファイルに損失の履歴も記録して覚えておけるようにしたのですが、保存する際にそのキーを追加するのを忘れてました。
GitHub のコードは修正しましたが、すでに途中まで学習したファイルを読み込む際は「その1行を消す」という対処で大丈夫です。その1行を消しても学習結果には影響しません。
わかりました。
160行目を消して動かしてみます。
ありがとうございました。
先日、学習を途中から再開させる方法をお尋ねしたmatuso2506です。
今日、正常に学習を1000から2000まで行うことができ、2000まででの推論でもかなり精度が上がったことがわかりました。
丁寧にご対応いただいた管理人様には深く感謝しております。
本当にありがとうございました。
以前、学習再開方法についてご質問させていただいたmatuso2506です。
学習後に出力されるチェックポイントなどの重みで推論を行う際、
適合率や再現率、IOUなどの評価指標を使い、モデルの精度や検出率を評価したいのですが、
それを行う方法がわかりません。
本サイトでは学習時の損失関数の推移を調べる方法が載っていますが、
もし、学習後のモデルの精度や検出率を評価する方法があれば教えていただきたく存じます。
よろしくお願いいたします。
コメントありがとうございます。
物体検出において、性能は mAP を使って評価するのが一般的です。詳細の記事で紹介しています。
https://pystyle.info/how-to-calculate-object-detection-metrics-map
評価が行えるようにスクリプトを追加しました。
https://github.com/nekobean/pytorch_yolov3
評価方法
python evaluate_custom.py –dataset_dir custom_dataset –weights train_output/yolov3_final.pth –config config/yolov3_custom.yaml –out 0.5
`–dataset_dir` にデータセット、`–weights` に学習途中のチェックポイント (.ckpt) または学習完了した重み (.pth) のいずれかを指定してください (いままで学習した重みが使えます)。詳しい使い方は記事にも追記しました。
早急かつ丁寧なご対応、ありがとうございます。
個人的にmAPなど機械学習の性能評価のことはまだ勉強し始めたばかりですので、
管理人様のサイト等で勉強させていただきたいと思います。
ありがとうございました。
以前、モデルの性能評価の方法についてご質問させていただいたmatuso2506です。
無事にモデルのPR曲線やAPを求めて性能を評価することができました。
もし可能でしたら、PR曲線やAPを求めるのに使用したIOUやTP,FPなどの数値をCSVファイルで出力するコードを実装していただくとありがたいです。
よろしくお願いいたします。
metrics_output/ 以下に detections.csv という名前で、列 Correct に「正解かどうか」、列 IOU に「マッチした矩形とのIOU (マッチしなかった場合は NaN) 」を記載した CSV を出力するようにスクリプトを修正しました。
早急なご対応、大変感謝しております。
無事に出力することができました。
画像検出の勉強になり、とても助かりました。
ありがとうございました。
論文にこちらのコードを参照したいのですが可能でしょうか?
その際、参考文献はどのように書けばいいかわかりますか??
コード自体を上げるわけではなくて、YOLO-v3で分類した結果として
このコードを使わせてもらいました。
使用した具体例は、自動車で使うシステムの特徴量の一つとして車両の有無を用いたいのですが、その際にMS-COCOを使ったYOLO-v3モデル作成のためにこちらのコードを参照させて頂きました。
コメントありがとうございます。
> 論文にこちらのコードを参照したいのですが可能でしょうか?
GitHub のコード https://github.com/nekobean/pytorch_yolov3 は YOLOv3 関連の解説記事のサンプルコードの位置づけですので、自由に使っていただいて構いません。参考文献への記載も任意で大丈夫です。
論文で YOLOv3 について言及する場合は、基本的には以下の元論文を参考文献に記載しておけば問題ないと思います。
“`
@article{yolov3,
title={YOLOv3: An Incremental Improvement},
author={Redmon, Joseph and Farhadi, Ali},
journal = {arXiv},
year={2018}
}
“`
> 自動車で使うシステムの特徴量の一つとして車両の有無を用いたい
自動車は MSCOCO に含まれているので、公式サイトで配布されている重み https://pjreddie.com/media/files/yolov3.weights をそのまま使ってもそれなりの精度で検出が行えます。https://github.com/nekobean/pytorch_yolov3 は DarkNet の .weights 形式の重みを指定しても動作します。方法については以下の記事でも紹介していますので、もしよろしければご参照ください。
YOLOv3 – 学習済みモデルで画像から人や車を検出する方法
https://pystyle.info/pytorch-yolov3-how-to-use-pretrained-model/
丁寧に返信くださり、ありがとうございます。
このサイトの記事で行った機械学習は転移学習と思われますが、転移学習での追加した層の構成(畳み込み層、ブーリング層、全結合層の数)を教えていただけませんか。
本サイトで行われている転移学習で、学習を行っている部分の層の構成を知りたいです。
コメントありがとうございます。
> 転移学習での追加した層の構成(畳み込み層、ブーリング層、全結合層の数)を教えていただけませんか。
この記事で使用している Pytorch 実装 https://github.com/nekobean/pytorch_yolov3 は、論文著者の実装 https://github.com/pjreddie/darknet から独自の変更は行っておりません。この記事で解説している学習方法では、公式サイトで配布されている ImageNet で学習した YOLOv3 の重み https://pjreddie.com/media/files/darknet53.conv.74 を重みの初期値として使用し、すべてのパラメータの調整するファインチューニング (fine-tuning) という形で学習を行っています。
ファインチューニングと転移学習の違いについては以下の記事で解説しています。
https://pystyle.info/pytorch-train-classification-problem-using-a-pretrained-model/#outline__3
YOLOv3 において、クラス数を変えた場合にモデルで変化する箇所は、出力層の直前の畳み込み層の出力数のみであり、ほかは変化しません。YOLOv3 のモデル構造は以下の記事で解説していますので、よろしければご参照ください。
https://pystyle.info/pytorch-yolov3/
返信ありがとうございます。
「YOLOv3 において、クラス数を変えた場合にモデルで変化する箇所は、出力層の直前の畳み込み層の出力数のみ」とありますが、
これは転移学習の場合の仕組みですか?
「すべての層のパラメータの調整する」というのと「出力層の直前の畳み込み層の出力数のみ変更する」というのは矛盾しているように思いました。
先程の返信の前者がサイトで扱ってるファインチューニングのことで、後者は転移学習のことを説明しているのでしょうか?
そこが分かりづらかったので、返信させていただきました。
申し訳ありません。私の方が勘違いしていました。
後半の「YOLOv3 において、クラス数を変えた場合にモデルで変化する箇所は、出力層の直前の畳み込み層の出力数のみ変更する」というのは
「モデルの層構造は変更せず、クラス数を変えると最終層の出力ノードの個数が変わる」という意味で、転移学習のことではなかったのですね。
大変失礼いたしました。
クラス分類モデルの場合、クラス数が変われば最後の層の出力数 (ノード数) を変える必要があり、
そうするとパラメータの数がかわるので、いずれにせよその層の学習はする必要があります。
問題はそれ以外のパラメータ数が変わらない層も学習するかどうかです。
・パラメータ数が変わらない他の層は学習しない → 転移学習
・パラメータ数が変わらない他の層も学習する → ファインチューニング
というのが私の認識です。YOLOv3 の場合、すべての層を学習するのでファインチューニングです。