
概要
Beautiful Soup の DOM ツリーのアクセス方法について解説します。
関連記事
[blogcard url=”https://pystyle.info/scraping-beautiful-soup-how-to-find-elements”]
[blogcard url=”https://pystyle.info/scraping-beautiful-soup-how-to-edit-dom-tree”]
サンプルの HTML
以下の HTML をサンプルとして使用します。
html = """
<html>
<head>
<title>ニュース</title>
</head>
<body>
<h1>ニュース</h1>
<div class="topic">
<h2>トピック一覧</h2>
<ul class="list" id="menu">
<li>トピック1</li>
<li>トピック2</li>
</ul>
</div>
<div class="images">
<h2>注目の画像</h2>
<ul class="menu">
<li><img src="sample1.jpg" alt="画像1"></li>
<li><img src="sample2.jpg" alt="画像2"></li>
</ul>
</div>
<p>お気に入りに<a href="sample.com">このサイト</a>を登録してください。</p>
</body>
</html>
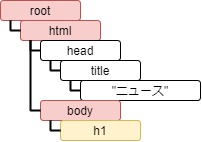
"""Beautiful Soup では、HTML テキストを解析し、以下のような DOM ツリーで表現します。
ルートノードは BeautifulSoup オブジェクト、要素は Tag オブジェクト、テキストは NavigableString オブジェクトで表されます。要素の検索、追加はこの階層構造を元に行いますので、解析する HTML の階層構造がどうなっているかをまず理解するようにしましょう。
root (BeautifulSoup)
└── html (Tag)
├── head (Tag)
│ └── title (Tag)
│ └── 'ニュース' (NavigableString)
└── body (Tag)
├── h1 (Tag)
│ └── 'ニュース' (NavigableString)
├── div (Tag)
│ ├── h2 (Tag)
│ │ └── 'トピック一覧' (NavigableString)
│ └── ul (Tag)
│ ├── li (Tag)
│ │ └── 'トピック1' (NavigableString)
│ └── li (Tag)
│ └── 'トピック2' (NavigableString)
├── div (Tag)
│ ├── h2 (Tag)
│ │ └── '注目の画像' (NavigableString)
│ └── ul (Tag)
│ ├── li (Tag)
│ │ └── img (Tag)
│ └── li (Tag)
│ └── img (Tag)
└── p (Tag)
├── 'お気に入りに' (NavigableString)
├── a (Tag)
│ └── 'このサイト' (NavigableString)
└── 'を登録してください。' (NavigableString)
説明のため、要素の情報を表示するヘルパー関数を定義します。
from bs4 import BeautifulSoup
soup = BeautifulSoup(html)
def print_element(elem):
if isinstance(elem, bs4.NavigableString):
print(type(elem), elem.string)
else:
print(type(elem), elem.name)機能一覧
| 名前 | 説明 |
|---|---|
Tag.parent |
親要素を参照する |
Tag.parents |
先祖要素を返すジェネレーター |
Tag.<TagName> (例: tag.h1) |
子孫要素の中で、指定した名前を持つ最初の要素を参照する |
Tag.contents |
子要素の一覧を参照する |
Tag.children |
子要素を返すジェネレーター |
Tag.<TagName> |
子要素を返すジェネレーター |
Tag.descendants |
子孫要素を返すジェネレーター |
Tag.previous_sibling |
1つ前の兄弟要素を参照する |
Tag.previous_siblings |
この要素より前のすべての兄弟要素を返すジェネレーター |
Tag.next_sibling |
1つ後の兄弟要素を参照する |
Tag.next_siblings |
この要素より後のすべての兄弟要素を返すジェネレーター |
Tag.string |
要素の値を参照する |
Tag.strings |
子孫要素の値を返すジェネレーター |
Tag.stripped_strings |
子孫要素の値を返すジェネレーター (文字列の前後の空白は削除) |
Tag.text |
子孫要素のすべての値を結合したテキストで取得する |
Tag.get_text(strip) |
子孫要素のすべての値を結合したテキストで取得する |
Tag.attrs |
属性及び属性値の一覧を参照する |
Tag["<AttributeName>"] (例: tag["class"]) |
指定した属性の属性値を参照する |
Tag.get("<AttributeName>", default) |
指定した属性の属性値を参照する |
Tag.get_attribute_list("<AttributeName>", default) |
指定した属性の属性値を参照する |
Tag.has_attr("<AttributeName>") |
指定した属性が存在するかどうかを調べる |
Tag.name |
要素の名前を参照する |
Tag.is_empty_element |
要素が空要素かどうかを調べる |
親要素を参照する
Tag.parent で親要素を参照できます。

tag = soup.html.body.h1
print_element(tag.parent)<class 'bs4.element.Tag'> body
先祖要素を参照する
Tag.parents は先祖要素を順番に返すジェネレーターです。
tag = soup.html.body.h1
for anc in tag.parents:
print_element(anc)<class 'bs4.element.Tag'> body <class 'bs4.element.Tag'> html <class 'bs4.BeautifulSoup'> [document]
子要素を参照する
Tag.contents は子要素の一覧をリストとして参照できます。
また、Tag.children は子要素を順番に返すジェネレーターになります。
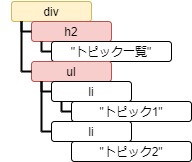
tag = soup.html.body.div
print(tag.contents)
for child in tag.children:
print_element(child)[<h2>トピック一覧</h2>, <ul class="list" id="menu"><li>トピック1</li><li>トピック2</li></ul>] <class 'bs4.element.Tag'> h2 <class 'bs4.element.Tag'> ul
また、Tag オブジェクト自体も子要素を順番に返すジェネレーターになります。
tag = soup.html.body.div
for child in tag:
print_element(child)<class 'bs4.element.Tag'> h2 <class 'bs4.element.Tag'> ul
子孫要素を参照する
タグ名で子孫要素を参照する
該当する要素が複数ある場合は、最初に見つかった子孫要素になります。
例えば、html の子孫には、2つの div タグがありますが、そのうち最初に見つかった1つ目の div タグの参照になります。
tag = soup.html.div
print_element(tag)<class 'bs4.element.Tag'> div
descendants で子孫要素を参照する
Tag.descendants は子孫要素を順番に返すジェネレーターになります。
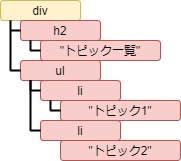
tag = soup.html.body.div
for des in tag.descendants:
print_element(des)<class 'bs4.element.Tag'> h2 <class 'bs4.element.NavigableString'> トピック一覧 <class 'bs4.element.Tag'> ul <class 'bs4.element.Tag'> li <class 'bs4.element.NavigableString'> トピック1 <class 'bs4.element.Tag'> li <class 'bs4.element.NavigableString'> トピック2
兄弟要素を参照する
1つ前の兄弟要素を参照する
Tag.previous_sibling で1つ前の兄弟要素を参照できます。
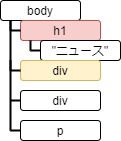
tag = soup.html.body.div
print_element(tag.previous_sibling)<class 'bs4.element.Tag'> h1
この要素より前のすべての兄弟要素を参照する
Tag.previous_siblings はこの要素より前のすべての兄弟要素を順番に返すジェネレーターです。
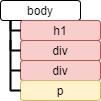
tag = soup.html.body.p
for prev in tag.previous_siblings:
print_element(prev)<class 'bs4.element.Tag'> div <class 'bs4.element.Tag'> div <class 'bs4.element.Tag'> h1
1つ後の兄弟要素を参照する
Tag.next_sibling で1つ前の兄弟要素を参照できます。
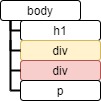
tag = soup.html.body.div
print_element(tag.next_sibling)<class 'bs4.element.Tag'> div
この要素より後のすべての兄弟要素を参照する
Tag.next_siblings はこの要素より後のすべての兄弟要素を順番に返すジェネレーターです。
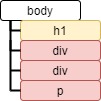
tag = soup.html.body.h1
for nxt in tag.next_siblings:
print_element(nxt)<class 'bs4.element.Tag'> div <class 'bs4.element.Tag'> div <class 'bs4.element.Tag'> p
要素の値を参照する
ある要素の値を参照する
Tag.string で要素の値を参照できます。値が存在しない要素の場合、この結果は None になります。

tag = soup.html.body.h1
print(tag.string) # ニュース
tag = soup.html.body.div
print(tag.string) # Noneニュース None
子孫要素のすべての値を参照する
Tag.strings は子孫要素の値を順番に返すジェネレーターになります。
また Tag.stripped_strings も子孫要素の値を順番に返すジェネレーターですが、前後の空白は削除された値を返します。
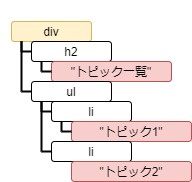
tag = soup.html.body.div
for s in tag.strings:
print(s)トピック一覧 トピック1 トピック2
子孫要素のすべての値を結合したテキストで取得する
Tag.text または Tag.get_text() で子孫要素のすべての値を結合し、1つのテキストとして取得します。strip=True を指定すると、前後の空白を削除します。
tag = soup.html.body.div
print(tag.get_text())トピック一覧トピック1トピック2
属性を参照する
属性及び属性値の一覧を参照する
Tag.attrs である要素の属性及び属性値を dict で参照できます。
tag = soup.html.body.ul
print(tag.attrs) # {'class': ['list'], 'id': 'menu'}{'class': ['list'], 'id': 'menu'}
Tag[<属性>] で要素のもつ <属性> の属性値を参照できます。
また、Tag.get(<属性>) でも <属性> の属性値を参照できます。こちらは第2引数で属性が存在しない場合に返すデフォルト値を指定できます。
返り値は class のように複数の値が許可された属性はリスト、そうでない属性は文字列で返します。常にリストで取得したい場合は Tag.get_attribute_list() を利用します。
指定した属性の属性値を参照する
print(tag["class"]) # ['list']
print(tag.get("class")) # ['list']
print(tag.get("id")) # menu
print(tag.get_attribute_list("id")) # ['menu']
print(tag.get("type", "hoge")) # hoge['list'] ['list'] menu ['menu'] hoge
指定した属性が存在するかどうかを調べる
# ul 要素に属性 `class` が存在するかどうかを調べる。
print(tag.has_attr("class")) # TrueTrue
要素名を参照する
Tag.name でその要素の要素名を取得できます。
tag = soup.html.body.ul
print(tag.name)ul
空要素かどうかを調べる
Tag.is_empty_element で img タグのように値を持たない空要素かどうかを調べられます。
tag = soup.img
print(tag.is_empty_element)True
コメント