
概要
requests モジュールまたは urllib.request モジュールと Beautiful Soup を使用した静的なページのスクレイピング手順について解説します。
スクレイピングの手順
1. HTML の DOM ツリーを把握する
まず、スクレイピングをしたい Web ページをブラウザ (ここでは Chrome を前提とします) で開きます。
開いたら、取得したい情報の要素を右クリックし、「検証」を選択します。すると、ブラウザの右サイドバーに「開発者ツール」が表示されるので、Element タブを選択します。
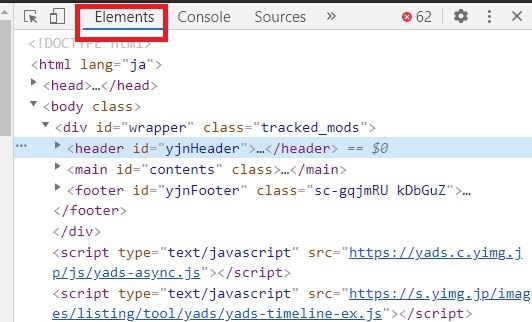
HTML は DOM ツリーと呼ばれる木構造になっており、スクレイピングでは DOM ツリーから必要な要素を見つける必要があるため、要素の親子関係がどうなっているかを把握することが重要です。
開発者ツールで確認できる HTML の注意点
Web ページによっては Javascript で動的にコンテンツを生成する作りになっています。 その場合、最初にサーバーから HTML を取得した段階ではそのコンテンツは HTML 上に存在していないことになります。 「開発者ツール」から確認できる HTML 構造は、今現在のものです。サーバーから取得した段階の HTML を確認したい場合は右クリックから「ページのソースを表示」を選択しましょう。
もし、「開発者ツール」上には存在し、「ページのソースを表示」で表示された HTML ソースコード上に存在しなかった場合、その要素は Javascript で後から生成されたものになります。スクレイピングで要素を検索した際に「開発者ツール」上にはあるのに要素が見つからない場合は大抵このパターンなので注意しましょう。
2. HTML を取得する
HTML の取得は先に述べた Javascript で動的に生成されたページかどうかで使用するツールが変わってきます。
- Javascript で動的に生成されたページのスクレイピング: selenium
- 静的なページ:
requestsモジュールまたはurllib.requestモジュール
今回は静的なページをスクレイピングする場合のやり方について解説します。 Javascript で動的に生成されたページのスクレイピングしたい場合は以下の記事を参照してください。
[blogcard url=”https://pystyle.info/scraping-tutorials-for-website-using-javascript”]
題材として、Webスクレイピング用のサンプルサイトとして こちらのページ を利用します。
requests モジュールを使って取得
requests モジュールは pip install requests でインストールできます。
Web ページの取得は簡単は、url を指定して requests.get(url) を呼び出します。返り値はレスポンスを表す Response オブジェクトになります。内容は Response.content で取得できます。
import requests
url = "https://pystyle.info/apps/scraping/"
res = requests.get(url)
if not res.ok:
print(f"ページの取得に失敗しました。status: {res.status_code}, reason: {res.reason}")
else:
html = res.contentResponse オブジェクトの属性やメソッドで以下の情報が取得できます。
| 属性またはメソッド | 概要 |
|---|---|
| encoding | 文字コード |
| headers | HTTP ヘッダー |
| url | ページを取得した URL |
| ok | HTTP ステータスコードが200かどうか |
| status_code | HTTP ステータスコード |
| reason | HTTP ステータスコードの理由 |
| iter_content() | コンテンツを1文字ずつ返す |
| iter_lines() | コンテンツを1行ずつ返す |
| res.json() | コンテンツが JSON の場合に JSON として解析して dict で返す |
| raise_for_status() | ページの取得に失敗した場合は例外を送出する |
urllib.request モジュールを使って取得
標準ライブラリの urllib.request モジュールでも Web ページを取得できます。
単に Web ページを取得するだけであれば、外部ライブラリを使わないこちらのやり方のほうがいいかもしれません。
import urllib.request
url = "https://pystyle.info/apps/scraping/"
req = urllib.request.Request(url)
with urllib.request.urlopen(req) as res:
html = res.read()3. 解析する
HTML の解析は BeautifulSoup がおすすめです。BeautifulSoup は pip install beautifulsoup4 でインストールできます。Beautiful Soup の詳しい使い方は以下のページを参照ください。
[blogcard url=”https://pystyle.info/scraping-beautiful-soup-how-to-find-elements”]
[blogcard url=”https://pystyle.info/scraping-beautiful-soup-how-to-refer-elements”]
[blogcard url=”https://pystyle.info/scraping-beautiful-soup-how-to-edit-dom-tree”]
スクレイピング練習用のサンプル には色の情報がテーブルで記載されています。こちらから色の名前と RGB の値を抽出してみます。

Response.content をBeautifulSoup オブジェクトに渡すことで、HTML を解析し、DOM ツリーが作成できます。
今回の場合、DOM ツリーは以下のようになっています。
import requests
from bs4 import BeautifulSoup
url = "https://pystyle.info/apps/scraping/"
res = requests.get(url)
soup = BeautifulSoup(res.content)root (BeautifulSoup)
└── html (Tag)
├── head (Tag)
│ ├── meta (Tag)
│ ├── title 'スクレイピング練習用のサンプル' (Tag)
│ └── link (Tag)
└── body (Tag)
└── main (Tag)
├── h2 '色の一覧' (Tag)
└── table (Tag)
├── thead (Tag)
│ └── tr (Tag)
│ ├── th '名前' (Tag)
│ ├── th 'RGB' (Tag)
│ └── th '色' (Tag)
└── tbody (Tag)
├── tr (Tag)
│ ├── td 'Black' (Tag)
│ ├── td '(0, 0, 0)' (Tag)
│ └── td '' (Tag)
├── tr (Tag)
│ ├── td 'Red' (Tag)
│ ├── td '(255, 0, 0)' (Tag)
│ └── td '' (Tag)
├── tr (Tag)
│ ├── td 'Green' (Tag)
│ ├── td '(0, 255, 0)' (Tag)
│ └── td '' (Tag)
├── tr (Tag)
│ ├── td 'Yellow' (Tag)
│ ├── td '(255, 255, 0)' (Tag)
│ └── td '' (Tag)
├── tr (Tag)
│ ├── td 'Blue' (Tag)
│ ├── td '(0, 0, 255)' (Tag)
│ └── td '' (Tag)
├── tr (Tag)
│ ├── td 'Magenta' (Tag)
│ ├── td '(255, 0, 255)' (Tag)
│ └── td '' (Tag)
├── tr (Tag)
│ ├── td 'Cyan' (Tag)
│ ├── td '(0, 156, 209)' (Tag)
│ └── td '' (Tag)
└── tr (Tag)
├── td 'White' (Tag)
├── td '(255, 255, 255)' (Tag)
└── td '' (Tag)
色の名前と RGB を取得するには以下のようにします。
soup.tbody.find_all("tr")でtbody要素以下のtr要素の一覧を取得するtr_tag.find_all("td")で各tr要素以下のtd要素の一覧を取得するtd要素の値 (例:Red、(255, 0, 255)) はtd_tag.stringで取得する
from pprint import pprint
data = []
for tr_tag in soup.tbody.find_all("tr"):
td_tags = tr_tag.find_all("td")
name = td_tags[0].string
rgb = td_tags[1].string
data.append({"name": name, "rgb": rgb})
pprint(data)[{'name': 'Black', 'rgb': '(0, 0, 0)'},
{'name': 'Red', 'rgb': '(255, 0, 0)'},
{'name': 'Green', 'rgb': '(0, 255, 0)'},
{'name': 'Yellow', 'rgb': '(255, 255, 0)'},
{'name': 'Blue', 'rgb': '(0, 0, 255)'},
{'name': 'Magenta', 'rgb': '(255, 0, 255)'},
{'name': 'Cyan', 'rgb': '(0, 156, 209)'},
{'name': 'White', 'rgb': '(255, 255, 255)'}]
目的の値が取得できました。
まとめ
スクレイピングの手順をまとめると以下のようになります。
- Web ページをブラウザで開いて、HTML の構造を把握する
- 「Ctrl + Shift + I」キーまたは「F12」を押して「開発者ツール」を開いて、取得したい周辺の HTML の DOM ツリー構造を把握する
- 「Ctrl + U」による「ソースコードの表示」を押して、対象の要素が存在する、つまり、Javascript で動的に作られたコンテンツでないことを確認する。
requestsモジュール、またはurllib.requestモジュールで Web ページの HTML を取得する- Beautiful Soup で解析する
コメント