
概要
fillna、interpolate で NaN の値を補間する方法について紹介します。
pandas.Series.interpolate
pandas.Series.interpolate() は、指定した方法で Series の値が NaN の要素を補間します。
Series.interpolate(self, method='linear', axis=0, limit=None, inplace=False, limit_direction='forward', limit_area=None, downcast=None, **kwargs)| 名前 | 型 | デフォルト値 |
|---|---|---|
| method | str | ‘linear’ |
| 補間方法 | ||
| axis | {0 or ‘index’, 1 or ‘columns’, None} | None |
| 補間する軸の方向 | ||
| limit | int, optional | |
| 連続する NaN は何個まで補間するかを1以上の整数で指定します。 | ||
| inplace | bool | False |
| inplace で処理を行うかどうか | ||
| limit_direction | {‘forward’, ‘backward’, ‘both’} | ‘forward’ |
| 補間する方向 | ||
| limit_area | {None, ‘inside’, ‘outside’} | None |
| 補間対象の領域 | ||
| downcast | optional, ‘infer’ or None, defaults to None | |
| downcast=”infer” の場合は、補間した結果、ダウンキャスト可能な場合はキャストします。(例: float -> int) | ||
| **kwargs | ||
| 補間を行う関数に渡すキーワード引数 | ||
| 名前 | 説明 |
|---|---|
| Series or None | 補間した結果。inplace=True の場合は None。 |
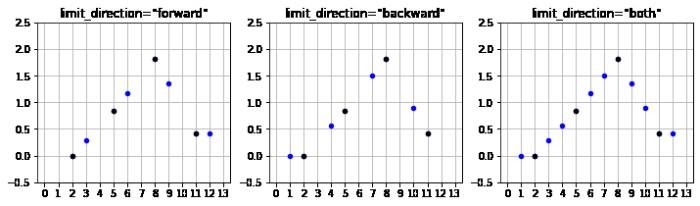
limit_direction, limit – 補間する方向を設定する
limit_direction で補間を行う方向を指定します。
- “forward”: 先頭 (最初の NaN でない要素) から末尾にかけて補間を行います。
- “backward”: 末尾 (最初の NaN でない要素) から先頭にかけて補間を行います。
- “both”: 「末尾 (最初の NaN でない要素) から先頭」と「末尾 (最初の NaN でない要素) から先頭」の両方向で補間を行います。

limit は、limit_direction 方向に補間する際に、連続する NaN は何個まで補間するか指定します。
例えば、3つ NaN が連続するとき、limit=2 の場合は2個の NaN まで補間します。

limit_direction="both" の場合、以下のように両方向に補間されます。

import pandas as pd
from IPython.display import display
s1 = pd.Series(
[None, None, 0.0, None, None, 0.84, None, None, 1.82, None, None, 0.42, None, None]
)
data = {"original": s1}
for limit_dir in ["forward", "backward", "both"]:
s2 = s1.interpolate(method="linear", limit=1, limit_direction=limit_dir)
data[limit_dir] = s2
pd.concat(data, axis=1).T| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| original | NaN | NaN | 0.0 | NaN | NaN | 0.84 | NaN | NaN | 1.82 | NaN | NaN | 0.42 | NaN | NaN |
| forward | NaN | NaN | 0.0 | 0.28 | NaN | 0.84 | 1.166667 | NaN | 1.82 | 1.353333 | NaN | 0.42 | 0.42 | NaN |
| backward | NaN | 0.0 | 0.0 | NaN | 0.56 | 0.84 | NaN | 1.493333 | 1.82 | NaN | 0.886667 | 0.42 | NaN | NaN |
| both | NaN | 0.0 | 0.0 | 0.28 | 0.56 | 0.84 | 1.166667 | 1.493333 | 1.82 | 1.353333 | 0.886667 | 0.42 | 0.42 | NaN |
元の Series で値がある点を黒、補間された点を青で描画すると、以下のようになります。
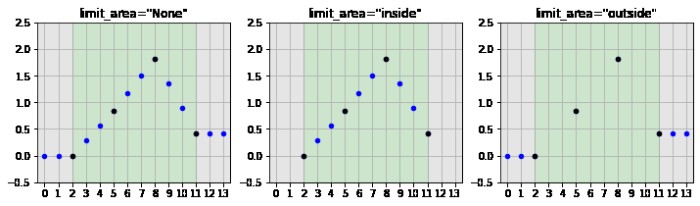
limit_area – 補間対象の領域を設定する
limit_area は、補間対象の領域を指定します。
- None: すべての NaN を補間対象とします。
"inside": 値に囲まれた NaN だけ補間対象とします。"outside": 値に囲まれていない NaN だけ補間対象とします。

s1 = pd.Series(
[None, None, 0.0, None, None, 0.84, None, None, 1.82, None, None, 0.42, None, None]
)
data = {"original": s1}
for limit_area in [None, "inside", "outside"]:
s2 = s1.interpolate(method="linear", limit_area=limit_area, limit_direction="both")
data[limit_area] = s2
pd.concat(data, axis=1).T| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| original | NaN | NaN | 0.0 | NaN | NaN | 0.84 | NaN | NaN | 1.82 | NaN | NaN | 0.42 | NaN | NaN |
| None | 0.0 | 0.0 | 0.0 | 0.28 | 0.56 | 0.84 | 1.166667 | 1.493333 | 1.82 | 1.353333 | 0.886667 | 0.42 | 0.42 | 0.42 |
| inside | NaN | NaN | 0.0 | 0.28 | 0.56 | 0.84 | 1.166667 | 1.493333 | 1.82 | 1.353333 | 0.886667 | 0.42 | NaN | NaN |
| outside | 0.0 | 0.0 | 0.0 | NaN | NaN | 0.84 | NaN | NaN | 1.82 | NaN | NaN | 0.42 | 0.42 | 0.42 |
元の Series で値がある点を黒、補間された点を青で描画すると、以下のようになります。
灰色の領域にある NaN は値に囲まれていないので outside、緑色の領域にある NaN は値に囲まれているので inside になります。
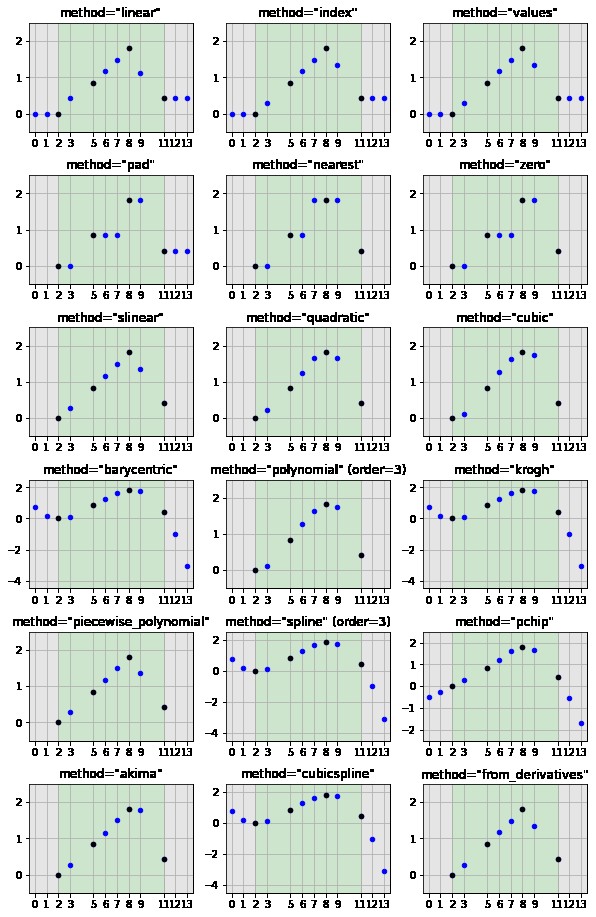
method – 補間方法を設定する
method で補間方法を指定できます。
spline、polynomialは、order引数で次元数を指定する必要があります。- 値に囲まれていない NaN を補間する方法と値に囲まれている NaN のみ補間する方法があります。スプライン補間のように区間ごとに補間する方法は値に囲まれている NaN しか補間できません。
| method | 内容 | 外挿の可否 | 備考 |
|---|---|---|---|
| linear | 線形補間 | ◯ | |
| index / values | インデックスを考慮した線形補間 | ◯ | |
| pad | 最も近い値で補完 | △ (前方のみ) | limit_direction=”forward” を指定 |
| nearest | 最近傍補間 | ✕ | |
| zero | 0次スプライン補間 | ✕ | |
| slinear | 1次スプライン補間 | ✕ | |
| quadratic | 2次スプライン補間 | ✕ | |
| cubic | 3次スプライン補間 | ✕ | |
| barycentric | 重心補間 | ◯ | |
| polynomial | 多項式補間 | ✕ | order 引数の指定が必要 |
| krogh | Krogh 補間 | ◯ | |
| piecewise_polynomial | 区間ごとに多項式補間 | ✕ | |
| spline | スプライン補間 | ◯ | order 引数の指定が必要 |
| pchip | 区分的3次エルミート補間 | ◯ | |
| cubicspline | 3次スプライン補間 | ◯ | |
| akima | 秋間補間 | ✕ | |
| from_derivatives | バーンスタイン基底の多項式による補間 | ✕ |
downcast – ダウンキャストが可能の場合はダウンキャストする
downcast="infer" の場合は、補間した結果、ダウンキャストが可能な場合はキャストします。
# NaN 以外はすべて整数だが、NaN が含まれているので型は float
s1 = pd.Series([0, None, None, 1, None, None, 2])
print(s1.dtype)
# NaN が補間されたことによりすべての値が整数になった
s2 = s1.interpolate(method="nearest", downcast="infer")
print(s2.dtype)float64 int64
pandas.DataFrame.interpolate
pandas.DataFrame.interpolate() は、指定した方法で DataFrame の値が NaN の要素を補間します。行または列ごとに補間を行う事以外は Sereis.interpolate() と使い方は同じです。
df = pd.DataFrame(
{"A": [0, 0, 0, 0], "B": [None, None, None, None], "C": [1, 1, 1, 1],}, dtype=float
)
# 列ごとに補間する
df.interpolate(axis=1, limit_direction="both")| A | B | C | |
|---|---|---|---|
| 0 | 0.0 | 0.5 | 1.0 |
| 1 | 0.0 | 0.5 | 1.0 |
| 2 | 0.0 | 0.5 | 1.0 |
| 3 | 0.0 | 0.5 | 1.0 |
axis – 補間を行う軸の方向
- axis=0: 列ごとに補間する
- axis=1: 行ごとに補間する
df = pd.DataFrame(
{"A": [0, None, None, 1], "B": [0, None, None, 1], "C": [0, None, None, 1],},
dtype=float,
)
display(df)
# 列ごとに補間する
display(df.interpolate(axis=0, limit_direction="both"))| A | B | C | |
|---|---|---|---|
| 0 | 0.0 | 0.0 | 0.0 |
| 1 | NaN | NaN | NaN |
| 2 | NaN | NaN | NaN |
| 3 | 1.0 | 1.0 | 1.0 |
| A | B | C | |
|---|---|---|---|
| 0 | 0.000000 | 0.000000 | 0.000000 |
| 1 | 0.333333 | 0.333333 | 0.333333 |
| 2 | 0.666667 | 0.666667 | 0.666667 |
| 3 | 1.000000 | 1.000000 | 1.000000 |
df = pd.DataFrame(
{"A": [0, 0, 0, 0], "B": [None, None, None, None], "C": [1, 1, 1, 1],}, dtype=float
)
display(df)
# 行ごとに補間する
display(df.interpolate(axis=1, limit_direction="both"))| A | B | C | |
|---|---|---|---|
| 0 | 0.0 | NaN | 1.0 |
| 1 | 0.0 | NaN | 1.0 |
| 2 | 0.0 | NaN | 1.0 |
| 3 | 0.0 | NaN | 1.0 |
| A | B | C | |
|---|---|---|---|
| 0 | 0.0 | 0.5 | 1.0 |
| 1 | 0.0 | 0.5 | 1.0 |
| 2 | 0.0 | 0.5 | 1.0 |
| 3 | 0.0 | 0.5 | 1.0 |
pandas.Series.fillna
pandas.Series.fillna() は、Series の値が NaN の要素を指定した方法で埋めます。
Series.fillna(self, value=None, method=None, axis=None, inplace=False, limit=None, downcast=None) → Union[ForwardRef(‘Series’), NoneType]| 名前 | 型 | デフォルト値 |
|---|---|---|
| value | scalar, dict, Series, or DataFrame | |
| 補間する値 | ||
| method | {‘backfill’, ‘bfill’, ‘pad’, ‘ffill’, None} | None |
| 補間する方法 | ||
| axis | {0 or ‘index’} | |
| 補間する軸の方向 | ||
| inplace | bool | False |
| inplace で処理を行うかどうか | ||
| limit | int | None |
| 連続する NaN は何個まで補間するかを1以上の整数で指定します。 | ||
| downcast | dict | is None |
| downcast=”infer” の場合は、補間した結果、ダウンキャスト可能な場合はキャストします。(例: float -> int) | ||
| 名前 | 説明 |
|---|---|
| Series or None | 補間した結果 |
value – 指定した値で埋める
value を指定した場合、NaN はその値で置換されます。
s1 = pd.Series([None, None, 1, None, None, 2, None, None])
s2 = s1.fillna(0)
print(s2)0 0.0 1 0.0 2 1.0 3 0.0 4 0.0 5 2.0 6 0.0 7 0.0 dtype: float64
dict を指定した場合、NaN のインデックスと同じ dict のキーの値で置換します。 Series を指定した場合、NaN のインデックスと同じ Series のインデックスの値で置換します。 対応するものが存在しない NaN はそのままになります。
s1 = pd.Series([None, None, 1, None, None, 2, None, None])
value = pd.Series([10, 20, 30, 40], index=[0, 1, 3, 6])
s2 = s1.fillna(value)
print(s2)0 10.0 1 20.0 2 1.0 3 30.0 4 NaN 5 2.0 6 40.0 7 NaN dtype: float64
method – 指定した方法で埋める
value の代わりに method を指定した場合、以下の方法で補間します。
- “backfill” / “bfill”: 直前の NaN 以外の値で置換します。
- “pad” / “ffill”: 直後の NaN 以外の値で置換します。

s1 = pd.Series([None, None, 0.0, None, None, 0.84, None, None])
data = {"original": s1}
methods = ["backfill", "bfill", "pad", "ffill"]
for method in methods:
s2 = s1.fillna(method=method)
method = f'method="{method}"'
data[method] = s2
pd.concat(data, axis=1).T| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | |
|---|---|---|---|---|---|---|---|---|
| original | NaN | NaN | 0.0 | NaN | NaN | 0.84 | NaN | NaN |
| method=”backfill” | 0.0 | 0.0 | 0.0 | 0.84 | 0.84 | 0.84 | NaN | NaN |
| method=”bfill” | 0.0 | 0.0 | 0.0 | 0.84 | 0.84 | 0.84 | NaN | NaN |
| method=”pad” | NaN | NaN | 0.0 | 0.00 | 0.00 | 0.84 | 0.84 | 0.84 |
| method=”ffill” | NaN | NaN | 0.0 | 0.00 | 0.00 | 0.84 | 0.84 | 0.84 |
downcast – ダウンキャストが可能の場合はダウンキャストする
downcast="infer" の場合は、補間した結果、ダウンキャストが可能な場合はキャストします。
# NaN 以外はすべて整数だが、NaN が含まれているので型は float
s1 = pd.Series([0, None, None, 1, None, None, 2])
print(s1.dtype)
# NaN が補間されたことによりすべての値が整数になった
s2 = s1.fillna(0, downcast="infer")
print(s2.dtype)float64 int64
pandas.DataFrame.fillna
pandas.DataFrame.fillna() は、DataFrame の値が NaN の要素を指定した方法で埋めます。行または列ごとに埋める事以外は Sereis.fillna() と使い方は同じです。
df = pd.DataFrame(
[
[1, 1, 1, 1, 1],
[None, None, None, None, None],
[2, 2, 2, 2, 2],
[None, None, None, None, None],
[3, 3, 3, 3, 3],
],
index=["a", "b", "c", "d", "e"],
columns=["A", "B", "C", "D", "E"],
dtype=float,
)
display(df)
# 列ごとに埋める
display(df.fillna(method="ffill", axis=0))| A | B | C | D | E | |
|---|---|---|---|---|---|
| a | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| b | NaN | NaN | NaN | NaN | NaN |
| c | 2.0 | 2.0 | 2.0 | 2.0 | 2.0 |
| d | NaN | NaN | NaN | NaN | NaN |
| e | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 |
| A | B | C | D | E | |
|---|---|---|---|---|---|
| a | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| b | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| c | 2.0 | 2.0 | 2.0 | 2.0 | 2.0 |
| d | 2.0 | 2.0 | 2.0 | 2.0 | 2.0 |
| e | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 |
df = pd.DataFrame(
[
[1, None, 2, None, 3],
[1, None, 2, None, 3],
[1, None, 2, None, 3],
[1, None, 2, None, 3],
[1, None, 2, None, 3],
],
index=["a", "b", "c", "d", "e"],
columns=["A", "B", "C", "D", "E"],
dtype=float,
)
display(df)
# 行ごとに埋める
display(df.fillna(method="ffill", axis=1))| A | B | C | D | E | |
|---|---|---|---|---|---|
| a | 1.0 | NaN | 2.0 | NaN | 3.0 |
| b | 1.0 | NaN | 2.0 | NaN | 3.0 |
| c | 1.0 | NaN | 2.0 | NaN | 3.0 |
| d | 1.0 | NaN | 2.0 | NaN | 3.0 |
| e | 1.0 | NaN | 2.0 | NaN | 3.0 |
| A | B | C | D | E | |
|---|---|---|---|---|---|
| a | 1.0 | 1.0 | 2.0 | 2.0 | 3.0 |
| b | 1.0 | 1.0 | 2.0 | 2.0 | 3.0 |
| c | 1.0 | 1.0 | 2.0 | 2.0 | 3.0 |
| d | 1.0 | 1.0 | 2.0 | 2.0 | 3.0 |
| e | 1.0 | 1.0 | 2.0 | 2.0 | 3.0 |
コメント
コメント一覧 (0件)
limit_area – 補間対象の領域を設定する箇所
None時のデータ表示は0,1のデータはNanなのにグラフでは、0で補間されているのはおかしくないですか。
コメントありがとうございます。
ご指摘の通り、サンプルコードの結果とグラフに乖離がありましたので、修正しました。
サンプルコードでは、limit_direction を指定していなかったため、デフォルトの “limit_direction=forward” の結果になっていた一方、図を描画する際は “limit_direction=both” を指定していたため、値と図の結果が異なっておりました。
limit_direction
“forward”: 先頭 (最初の NaN でない要素) から末尾にかけて補間を行います。
“backward”: 末尾 (最初の NaN でない要素) から先頭にかけて補間を行います。
“both”: 「末尾 (最初の NaN でない要素) から先頭」と「末尾 (最初の NaN でない要素) から先頭」の両方向で補間を行います。
この文章は表示に分かりやすい説明してくれて、図解もあるので、本当にありがとうございます。
ちなみに、最新のpandasは’pad’も追加されたが、’zero’と何か違いますか?ご教授お願いします。
コメントありがとうございます。
確認したところ、zero は後ろ方向に最も近い値で補完するのに対し、pad は前方向に最も近い値に補完されるようでした。
例:
補完前: NaN 1 NaN 2 NaN 3 NaN
↓
zero による補完後: 1 1 2 2 3 3 NaN
pad による補完後: NaN 1 1 2 2 3 3