
概要
衣類の画像データセット Fashion-MNIST を題材に、Pytorch で CNN モデルの構築、学習、及び推論を行う方法を学ぶチュートリアルです。
環境
コード全体は GitHub にあります。
このコードは、以下の環境で実行しました。
- OS
- Ubuntu: 18.04
- ライブラリ
- pytorch: 1.3.1
- torchvision: 0.4.2
- GPU の実行環境
- GPU: GeForce GTX 1080
- CUDA: 10.1
- CuDNN: 7
- CPU の実行環境
- CPU: Intel(R) Core(TM) i7-6700K CPU @ 4.00GHz
- メモリ: 16G
必要なモジュールを import する。
from collections import defaultdict
import matplotlib.pyplot as plt
import numpy as np
import torch
import torch.nn as nn
import torchvision.datasets as datasets
import torchvision.transforms as transformsFashion-MNIST
Fashion-MNIST は、オンラインショップ Zalando 上の衣類の画像から作成されたデータセットです。 6万枚の学習データ、1万枚のテストデータで構成されています。 各サンプルは大きさが 28×28 のグレースケール画像で、10クラスのいずれかがラベル付けされています。 機械学習アルゴリズムのベンチマークとして広く使われてきた MNIST を参考にして、作成されました。

Fashin-MNIST を読み込む。
Fashin-MNIST は torchvision の datasets.FashionMNIST クラスで提供されています。
torchvision.datasets.FashionMNIST(
root, train=True, transform=None, download=False)- 引数
root: データセットを保存するディレクトリのパスを指定します。train:Trueを指定した場合は学習データ、Falseを指定した場合はテストデータをダウンロードします。transform: 画像に対して行う前処理を指定します。今回は、transforms.ToTensor のみを指定しました。 この Transformer は、画素値を範囲が [0, 255] の uint8 型から範囲が [0, 1] の float32 型にし、Pytorch で扱う Tensor に変換を行います。download:Trueを指定した場合は、データセットがローカルにない場合は、ネットからダウンロードします。
FashionMNIST オブジェクトを作成したら、utils.data.DataLoader に渡して、DataLoader を作成します。 この DataLoader は、指定したデータセットからデータを取得し、ミニバッチを作成して返す役割があります。
data_transform = transforms.ToTensor()
# 学習データを読み込む DataLoader を作成する。
train_dataset = datasets.FashionMNIST(
root="datasets", train=True, transform=data_transform, download=True
)
train_data_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=64, shuffle=True
)
# テストデータを読み込む DataLoader を作成する。
test_dataset = datasets.FashionMNIST(
root="datasets", train=False, transform=data_transform, download=True
)
test_data_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=64, shuffle=True
)Fashion-MNIST の中身を確認する。
FashionMNIST クラスの以下の属性で、クラス一覧や各画像、ラベルを取得できます。
FashionMNIST.classes(list): クラス名一覧FashionMNIST.class_to_idx(dict): クラス名、値がクラス ID の辞書FashionMNIST.data(Tensor): 画像一覧FashionMNIST.targets(Tensor): ラベル一覧
クラス一覧は以下のようになっています。
| クラス ID | クラス名 (英語) | クラス名 (日本語) |
|---|---|---|
| 0 | T-shirt/top | Tシャツ/トップス |
| 1 | Trouser | パンツ/ボトムズ |
| 2 | Pullover | セーター |
| 3 | Dress | ドレス |
| 4 | Coat | コート |
| 5 | Sandal | サンダル |
| 6 | Shirt | シャツ |
| 7 | Sneaker | スニーカー |
| 8 | Bag | バッグ |
| 9 | Ankle boot | ブーツ |
matplotlib で各クラスのサンプルを1つずつ表示して、確認します。
# 各クラスのラベルを持つサンプルを1つずつ取得する。
class_ids, sample_indices = np.unique(train_dataset.targets, return_index=True)
fig = plt.figure(figsize=(10, 4))
fig.suptitle(
"Examples of every class in the Fashion-MNIST dataset", fontsize="x-large"
)
for i in class_ids:
img = train_dataset.data[sample_indices[i]]
class_name = train_dataset.classes[i]
ax = fig.add_subplot(2, 5, i + 1)
ax.set_title(f"{i}: {class_name}")
ax.set_axis_off()
ax.imshow(img, cmap="gray")
plt.show()
CNN モデルを作成する
Pytorch で今回使用する以下の CNN モデルを作成していきます。
| No | 層 | 層のパラメータ | 出力の形状 (B, C, H, W) |
|---|---|---|---|
| 1 | 畳み込み層 | 出力数: 32 カーネルサイズ: (3, 3) ストライド: (1, 1) パディング: (1, 1) |
(None, 32, 28, 28) |
| 2 | ReLU | (None, 32, 28, 28) | |
| 4 | Max Pooling | カーネルサイズ: (2, 2) ストライド: (2, 2) |
(None, 32, 14, 14) |
| 3 | 畳み込み 層 | 出力数: 64 カーネルサイズ: (3, 3) ストライド: (1, 1) パディング: (1, 1) |
(None, 64, 14, 14) |
| 2 | ReLU | (None, 64, 14, 14) | |
| 4 | Max Pooling | カーネルサイズ: (2, 2) ストライド: (2, 2) |
(None, 64, 7, 7) |
| 6 | Flatten | (None, 3136) | |
| 5 | ドロップアウト | 脱落率: 0.5 | (None, 3136) |
| 7 | 全結合層 | 出力数: 128 | (None, 128) |
| 8 | ReLU | (None, 128) | |
| 9 | ドロップアウト | 脱落率: 0.5 | (None, 128) |
| 10 | 全結合層 | 出力数: 10 | (None, 10) |
| 11 | Log Softmax | (None, 10) |
コード
class Net(nn.Module):
def __init__(self):
super().__init__()
self.features = nn.Sequential(
nn.Conv2d(1, 32, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(32, 64, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2),
)
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(64 * 7 * 7, 128),
nn.ReLU(),
nn.Dropout(),
nn.Linear(128, 10),
nn.LogSoftmax(dim=1),
)
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x解説
Pytorch でモデルを作成するには、まず torch.nn.Module クラスを継承したクラスを作ります。
__init__() 内でそのモデルで使用する層を作成します。
畳み込み層
畳み込み層は torch.nn.Conv2d で作成します。 Keras と違い、Pytorch では入力のテンソルのチャンネル数も明示的に指定する必要があります。
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0)- 引数
- in_channels: 入力のチャンネル数
- out_channels: 出力のチャンネル数
- kernel_size: カーネルサイズ
- stride: ストライド (デフォルトは1)
- stride: パディング (デフォルトは0)
Max Pooling
Max Pooling は torch.nn.MaxPool2d で作成します。
torch.nn.MaxPool2d(kernel_size, stride=None, padding=0)- 引数
- kernel_size: カーネルサイズ
- stride: ストライド (デフォルトは kernel_size と同じ値)
- stride: パディング (デフォルトは0)
全結合層
全結合層は torch.nn.Linear で作成します。
torch.nn.Linear(in_features, out_features)- 引数
- in_channels: 入力のチャンネル数
- out_channels: 出力のチャンネル数
活性化関数
ReLU は torch.nn.ReLU、log softmax は torch.nn.LogSoftmax で作成します。
ドロップアウト
ドロップアウトは torch.nn.Dropout で作成します。
torch.nn.Dropout(p=0.5)- 引数
- p: 脱落率 (デフォルトは0.5)
損失関数を作成する。
出力層の活性化関数を log softmax としたので、それに合わせて、損失関数は torch.nn.NLLLoss を選択します。
nll_loss = nn.NLLLoss()デバイスを選択する
計算を実行するデバイスを選択します。 デフォルトでは、計算は CPU で実行するようになっていますが、CUDA が利用可能な場合は GPU で実行するようにします。 GPU が使用可能かどうかは torch.cuda.is_available() の値で確認できます。
GPU で実行する場合、計算に必要なテンソルはすべて GPU メモリ上にある必要があるので、モデルを Module.to() で GPU に転送します。 CPU 実行の場合は、メモリ上にすでにデータがあるため、なにも行われません。
# 計算を実行するデバイスを選択する。
# CUDA が利用可能な場合は、GPU、そうでない場合は CPU を選択する。
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# モデルを計算を実行するデバイスに転送する。
model = Net().to(device)最適化手法を選択する
モデルの重みパラメータの更新方法を選択します。 今回は Adam という手法て最適化を行います。
モデルで学習が必要なパラメータの一覧は Module.parameters() で取得できるので、それを torch.optim.Adam に渡して、Optimizer を作成します。
# Optimizer を作成する。
optim = torch.optim.Adam(model.parameters())学習を行う関数を作成する
1エポック分の学習を行う処理を関数にします。
コード
def train(model, device, data_loader, optim):
"""
1エポック分の学習を行う。
:param model: モデル
:param device: デバイス
:param data_loader: Data Loader
:param optim: Optimizer
"""
# モデルを学習モードに設定する。
model.train()
total_loss = 0
total_correct = 0
for data, target in data_loader:
# データ及びラベルを計算を実行するデバイスに転送する。
data, target = data.to(device), target.to(device)
# 順伝搬を行う。
output = model(data)
# 損失関数の値を計算する。
loss = nll_loss(output, target)
total_loss += float(loss)
# 逆伝搬を行う。
optim.zero_grad()
loss.backward()
# パラメータを更新する。
optim.step()
# 確率の最も高いクラスを予測ラベルとする。
pred_target = output.argmax(dim=1)
# 正答数を計算する。
total_correct += int((pred_target == target).sum())
# 損失関数の値の平均及び精度を計算する。
avg_loss = total_loss / len(data_loader.dataset)
accuracy = total_correct / len(data_loader.dataset)
return avg_loss, accuracy解説
Module.train() で学習モードに設定します。 Batch Normalization や Dropout などは学習時と評価時で挙動が変わるため、明示的に設定する必要があります。
DataLoader はイテレータになっており、1回のループごとに、バッチサイズ分のデータ及びラベルを返します。データセットのすべてのサンプルを返した場合はループを抜けるようになっています。
ループ内では以下の順番で処理を行います。
モデル同様、データ及びラベルを計算を実行するデバイスに転送します。
data, target = data.to(device), target.to(device)データをモデルに渡して、順伝搬を行います。
output = model(data)損失を計算します。
loss = nll_loss(output, target)Pytorch では、逆伝搬によって勾配を計算したあと、前回計算した勾配がある場合、それに今回計算した勾配を加算するようになっています。この仕様は RNN の学習では便利ですが、今回の CNN の学習では勾配を累加する必要はないので、逆伝搬を行う前に、勾配を Optimizer.zero_grad() で初期化します。
optim.zero_grad()逆伝搬を行い、勾配を計算します。
loss.backward()Optimizer で計算した勾配を元に、モデルの重みパラメータを更新します。
optim.step()学習の履歴を確認するために、精度を計算します。
モデルの出力のうち、確率の最も高いクラスを予測ラベルとします。
pred_target = output.argmax(dim=1)予測ラベル pred_target と正解ラベル target を比較し、一致する数、つまり、正答数を計算します。
total_correct += int((pred_target == target).sum())全サンプル数は len(data_loader.dataset) で取得できるので、この値で除算することで損失の平均及び精度を計算します。
avg_loss = total_loss / len(data_loader.dataset)
accuracy = total_correct / len(data_loader.dataset)評価を行う関数を作成する
モデルが過学習を起こしていないか確認するために、各エポックごとにテストデータに対する損失の平均及び精度を計算する関数も用意します。
コード
def test(model, device, data_loader):
"""
テストデータに対する損失の平均及び精度を計算する。
:param model: モデル
:param device: デバイス
:param data_loader: Data Loader
"""
# モデルをテストモードに設定する。
model.eval()
with torch.no_grad():
total_loss = 0
total_correct = 0
for data, target in data_loader:
# データ及びラベルを計算を実行するデバイスに転送する。
data, target = data.to(device), target.to(device)
# 順伝搬する。
output = model(data)
# 損失を計算する。
loss = nll_loss(output, target)
total_loss += float(loss)
# 確率の最も高いクラスを予測ラベルとする。
pred_target = output.argmax(dim=1)
# 正答数を計算する。
total_correct += int((pred_target == target).sum())
# 損失の平均及び精度を計算する。
avg_loss = total_loss / len(data_loader.dataset)
accuracy = total_correct / len(data_loader.dataset)
return avg_loss, accuracy解説
Module.eval()) で学習モードに設定します。 Batch Normalization や Dropout などは学習時と評価時で挙動が変わるため、明示的に設定する必要があります。
コンテキストマネージャー torch.no_grad() を使うと、そのコンテキスト中での計算では、勾配計算に必要な情報をメモリ上に保存しなくなります。 評価時は勾配を計算する必要がないため、メモリ節約のために、このコンテキスト中で計算を行います。
with torch.no_grad():
...学習する。
実際に学習を行ってみます。 エポック数は50とし、各エポックごとに学習、評価を順番に実行します。
n_epochs = 50
history = defaultdict(list)
for epoch in range(n_epochs):
# 1エポック分、学習する。
train_loss, train_accuracy = train(model, device, train_data_loader, optim)
history["train_loss"].append(train_loss)
history["train_accuracy"].append(train_accuracy)
# 評価する。
test_loss, test_accuracy = test(model, device, test_data_loader)
history["test_loss"].append(test_loss)
history["test_accuracy"].append(test_accuracy)
print(
f"epoch {epoch + 1} "
f"[train] loss: {train_loss:.6f}, accuracy: {train_accuracy:.0%} "
f"[test] loss: {test_loss:.6f}, accuracy: {test_accuracy:.0%}"
)損失関数の値の推移をグラフ化する。
matplotlib で損失、精度の推移を描画します。
epochs = np.arange(1, n_epochs + 1)
fig, [ax1, ax2] = plt.subplots(1, 2, figsize=(8, 3))
# 損失の推移
ax1.set_title("Loss")
ax1.plot(epochs, history["train_loss"], label="train")
ax1.plot(epochs, history["test_loss"], label="test")
ax1.set_xlabel("Epoch")
ax1.legend()
# 精度の推移
ax2.set_title("Accuracy")
ax2.plot(epochs, history["train_accuracy"], label="train")
ax2.plot(epochs, history["test_accuracy"], label="test")
ax2.set_xlabel("Epoch")
ax2.legend()
plt.show()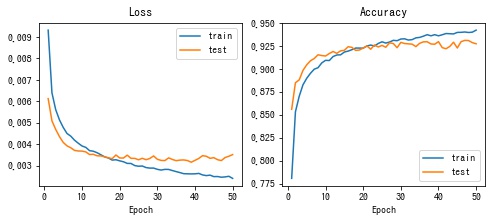
50 エポック分学習し、テストデータに対する精度が 93% のモデルを作ることができました。
まとめ
Fashion-MNIST を題材に、Pytorch で CNN モデルの構築、学習、及び推論を行う方法について見てきました。 Pytorch は今回のように単純なモデルからより複雑なモデルまで、シンプルにコーディングできる柔軟性に優れたライブラリです。
コメント